[笔记]Large-scale behavioral user targeting
用户行为定向的目的是根据用户的历史行为,来选择最合适的广告投放,按如下思路介绍:
- 模型、目标、算法
- 大规模数据上的应用技巧
- 数据压缩
- 特征选择和变换
- 生成训练集合测试集
- 并行的Multiplicative迭代
- 实验设定&结论
模型、目标、算法
a.模型
$$p(y) = \frac{{{\lambda ^y}\exp \left( { - \lambda } \right)}}{{y!}},\; {\lambda _i}={w^T}{x_i} $$ $y$:预测CTR(click-through rate),即用户某个特定类别上的点击率。 $x$:表示广告的点击, 用户的浏览行为,也可以购买、搜索等等行为。 $\lambda_t$:为相应的控制点击行为到达频繁性的参数。 点击行为是离散到达的随机变量,对数量最自然的描述规则是泊松分布。b.目标
优化目标:
最大化似然函数:
$$
\prod\limits_i^n {p\left( {{{\mathbf{y}}_i}} \right)} = \prod\limits_i^n {\frac{{{{\left( {{{\mathbf{w}}^T}{{\mathbf{x}}_i}} \right)}^{{{\mathbf{y}}_i}}}\exp \left( { - {{\mathbf{w}}^T}{{\mathbf{x}}_i}} \right)}}{{{{\mathbf{y}}_i}!}}}
$$
转求常用log似然:
$$l\left( y \right) = \log L\left( y \right) = \sum\limits_i^{} {\left( {{y_i}\log \left( \lambda \right) - \lambda - \log \left( {{y_i}!} \right)} \right)} $$
c.算法
1.梯度下降gd, 2.bfgs 3.multiplicative rule. 梯度下降更新规则: $$\Delta w = \frac{{\partial l\left( y \right)}}{{\partial {w_j}}} = \sum\limits_i {\left( {\frac{{{y_i}}}{{{\lambda _i}}}{x_{ij}} - {x_{ij}}} \right)} $$ (作者实际上采用multiplicative进行迭代,15-20轮收敛) CTR公式: $$CT{R_{ik}} = \frac{{\lambda _{ik}^{click} + \alpha }}{{\lambda _{ik}^{view} + \beta }}$$- 符号说明:$i,j,k$分别表示用户,特征,广告类型
- 注1:训练数据平滑,对于CTR公式的$\alpha \beta$`按每个类别计算,结果为给新用户推荐最热的类别。
- 注2:$\lambda = {w^T}x$为什么不用指数型$bda = \exp \left( {{w^T}x} \right)$,使用线性形式。初衷是方便在线计算,对于新的线上用户行为,$bda ' = \lambda {\delta ^{\Delta t}} + {w_j}\Delta {x_j}$
- 注3:为什么用NMF,W用来表示用户兴趣权重的,如果用户对某类广告不感兴趣,我们把它调为零即可。
- 注4:对于每个特征的权重$w_kj$的初始化可以用两种方式进行,
- a.类似TF-IDF:$${w_{kj}} \leftarrow \frac{{\sum\nolimits_i {\frac{{{y_{ik}}{x_{ij}}}}{{\sum\nolimits_{j'} {{x_{ij'}}} }}} }}{{\sum\nolimits_i {{x_{ij}}} }}$$
- b.全局类别上进行$${w_{kj}} \leftarrow \frac{{\sum\nolimits_i {\left( {{y_{ik}}{x_{ij}}} \right)\sum\nolimits_i {\left( {{y_{ik}}} \right)} } }}{{\sum\nolimits_{j'} {\left[ {\sum\nolimits_i {{y_{ik}}{x_{ij'}}} \sum\nolimits_i {{x_{ij'}}} } \right]} }}$$
b的思考出发点是部分类别的模型训练时间较长,给一个较适合的初值,可能使得整体迭代数据速度变快。
大规模数据的应用技巧
1.log数据的预处理,指定数据的字段抽取,以cookie为单位合并数据。
2.再以用户和时间为组合键,按时间间隔合并次数 ,这里时间间隔需要和模型所需一致。一个月的数据能减少到2-3TB(这里尚未进行广告分类)
特征选择和反向索引
广告点击、页面浏览、和搜索query,这些特征空间比较复杂和稀疏,作者使用频次阈值进行筛选,得到(特征类型 click / search / view,实体entity,freq)组合,不选择互信息,互信息容易受数据稀疏影响。最后输出为3类特征的词典,从实验配置可以认为是ad_id、page_id、query,三种词典。得到上述词典以后,特征向量可以用(下标,值)的形式存储,下标指词典的偏移。
trick 1.特征过滤卡频次用cookie为单位计数的原因是防爬虫
trick 2.直接对特征卡频次,这样无需做排序取topN
trick 3.在无需排序归并的阶段,reducer可以用值排序。这样避免对复杂key进行排序,增加时耗
生成训练集合测试集
如图显示,通过滑动窗口的采集方式,可以在$o(1)$的时间内完成特征数据的生成。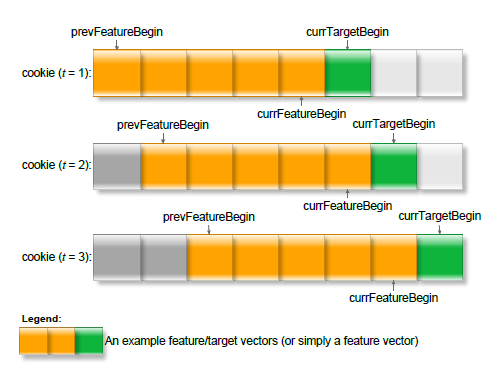
数据驱动的权重更新
这里主要提及下权重更新的并行化
1.通过一个稀疏矩阵D,我们想估计一个dense的权重矩阵W。给定$Y$,$X$,求得$\arg {\max _w}\log p\left( {{Y^T}|W{X^T}} \right)$的解$W^*$. (按:这里和目标泊松分布log-似然函数有关联)
2.${Y^T} \approx W{X^T}$,可以复用NMF非负矩阵分解中的高效乘法方式,通过log似然进行约束。
a. W是dense的矩阵,因为集群节点内存限制,我们需要拆开读入。由于拆以后计算$W{X^T}$复杂度较高,引入下一步的内存caching
b. In-memory Caching.对样本xy进行cache,预先求得cache内数据的 $\sum\nolimits_i {\frac{{{y_{ik}}{x_{ij}}}}{{{\lambda _{ik}}}}} $ 向后传递。
c. 按k为key进行reduce,最后累积更新到权重$W$。伪代码在论文4.5.3节
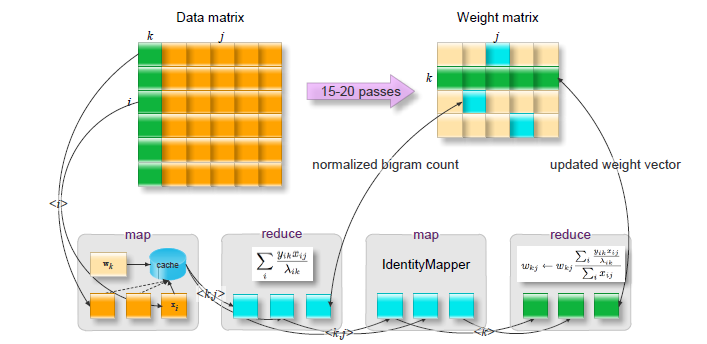
实验部分:
- 数据和参数
a.数据来源,广告点击,页面浏览,搜索query
b.效果衡量方式,1.baseline对比,见下表CTR lift,2.ROC曲线比较。60种主要BT行为 - 基线模型: Logistic Regression,分别为两个模型的结果积在一起,一部分预测下一天的点击,一部分预测下一小时点击。
实验结果:
a.数据量方面: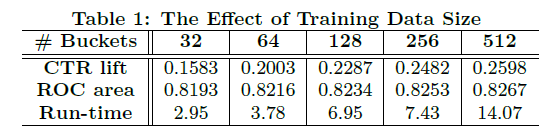
数据均分为512份,训练集不同的量带来的效果如图。
b.特征方面比较: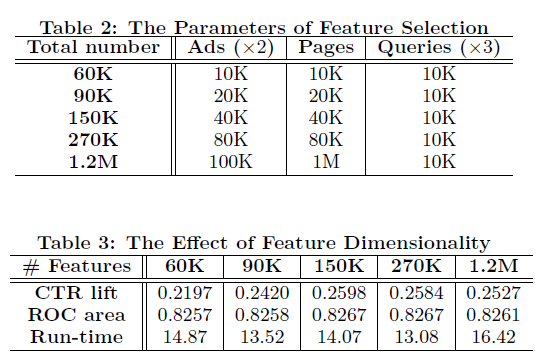
(PS.之所以控制特征为ads和pages变化是因为,query在点击预估的影响比较小)
(之前的加速措施使得训练时间有不受特征数目显著影响的特性)
c.target时间窗方面比较(意义可能不大,略):
d.分层抽样的效果
用户分三类:1.有点击行为 2.无广告点击,有广告view。3.广告点击和广告view都无
需要对后两类用户进行采样,第一栏的数字代表采样率。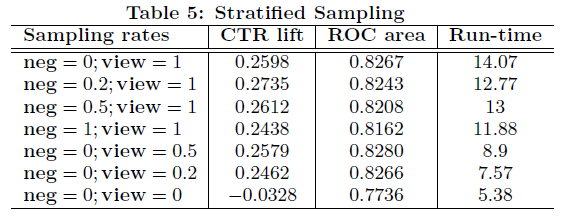
(负样本只对分母有影响,而且是提前算好的。结果看一个较小的neg采样组合一个较大的view采样可以带来一个比较好的效果)
e.引入时间间隙,模拟训练。
因为在线的训练的时候,有data延迟,在特征时间窗和目标时间窗中间插入一个间隙。带来的效果对比,右边是模拟在线的时候的效果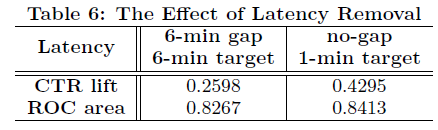
可以看到如果无间隙的时候,CTR有显著收益,说明实时的特征对CTR预估影响较大。
总结:作者根据用户历史行为预测用户对不同类别广告的CTR,同时给了在大规模数据上的实现框架。
(summarizes by:shawn_xiao@baidu)
引文:
[1]Chen, Ye,Pavlov, Dmitry,Canny, John, Large-scale behavioral targeting, [2010]