Gradient Boosting Decision Tree[下篇]
这篇笔记里面会继续介绍上篇GB理论的具体用法,对不同的loss function展开讨论:最小均方误差(LS)和最小绝对值误差(LAD),Huber(M)函数,三者主要是用在回归问题。接着再看GB理论怎么用在二分类和多分类上。
有没有发现写了这么多,还是没有点题”GBDT”,先记下,且往下看
纸上得来终觉浅,希望能组织一波小伙伴把模型实现个遍嘞
回顾下:上一篇结尾部分,我们给出了通用的GB框架:
- ${F_0}\left( {\bf{x}} \right) = \arg {\min _\rho }\sum\nolimits_{i = 1}^N {L\left( {{y_i},\rho } \right)} $
- $For\;m = 1\;to\;M\;do:$
- ${{\tilde y}_i} = - {\left[ {{{\partial L\left( {{y_i},F\left( {{{\bf{x}}_i}} \right)} \right)} \over {\partial F\left( {{{\bf{x}}_i}} \right)}}} \right]_{F\left( {\bf{x}} \right) = {F_{m - 1}}\left( {\bf{x}} \right)}},i = 1,N$
- ${{\bf{a}}_m} = \arg {\min _{{\bf{a}},\beta }}{\sum\nolimits_{i = 1}^N {\left[ {{{\tilde y}_i} - \beta h\left( {{{\bf{x}}_i};{\bf{a}}} \right)} \right]} ^2}$
- ${\rho _m} = \arg \mathop {\min }\limits_\rho \sum\nolimits_{i = 1}^N {L\left( {{y_i},{F_{m - 1}}\left( {{{\bf{x}}_i}} \right) + \rho h\left( {{{\bf{x}}_i};{{\bf{a}}_m}} \right)} \right)} $
- ${F_m}\left( {\bf{x}} \right) = {F_{m - 1}}\left( {\bf{x}} \right) + {\rho _m}h\left( {{\bf{x}};{{\bf{a}}_m}} \right)$
- $end For$
将若干learner $h({\bf x}_i;{\bf a})$用mixture方式进行组合最小化loss function,根据不同的loss function,第4行的负梯度计算也不同,下面介绍下几个常用的loss function:
最小均方差(LS)回归
loss function为$L\left( {y,F} \right) = {{{{\left( {y - F} \right)}^2}} \over 2}$。在$m$轮对$F_{m-1}$求导得到梯度,负梯度pseudore-response为${{\tilde y}_i} = {y_i} - {F_{m - 1}}\left( {{{\bf{x}}_i}} \right)$。通用框架中第4行只需要简单地拟合当前的残差,第5行线搜索步长$\rho _m$可以等价为第4行中的$\beta _m$。以最小均方差为loss function的可以推出残差拟合的级联方法,这也是最常见的形式。LS_Boost流程整理如下:
$$\eqalign{
& For\;m = 1\;to\;M\;do: \cr
& \;\;\;\;{y_i} = {y_i} - {F_{m - 1}}\left( {{{\bf{x}}_i}} \right),\;i = 1,N \cr
& \;\;\;\;\left( {{\rho _m},{{\bf{a}}_m}} \right) = \mathop {\arg \min }\limits_{{\bf{a}},\rho } {\sum\limits_{i = 1}^N {\left[ {{{\tilde y}_i} - \rho h\left( {{{\bf{x}}_i};{\bf{a}}} \right)} \right]} ^2} \cr
& \;\;\;\;{F_m}\left( {\bf{x}} \right) = {F_{m - 1}}\left( {\bf{x}} \right) + {\rho _m}h\left( {{\bf{x}};{{\bf{a}}_m}} \right) \cr
& endFor\; \cr} $$
最小绝对值误差(LAD)回归
loss function 为$L\left( {y,F} \right) = \left| {y - F} \right|\;$,可以得到负梯度为pseudore-response
$${{\tilde y}_i} = - {\left[ {{{\partial L\left( {{y_i},F\left( {{{\bf{x}}_i}} \right)} \right)} \over {\partial F\left( {{{\bf{x}}_i}} \right)}}} \right]_{F\left( {\bf{x}} \right){\rm{ = }}{F_{m - 1}}\left( {\bf{x}} \right)}} = sign\left( {{y_i} - {F_{m - 1}}\left( {{{\bf{x}}_i}} \right)} \right)$$,这个求导过程放在附录思考[1]。
我们需要一组分类器$h({\bf x};{\bf a})$去拟合残差的符号(pseudore-response为符号函数值,拟合pseudore-response即拟合残差的符号)。通过线搜索得到
$$\eqalign{
& {\rho _m} = \arg \mathop {\min }\limits_\rho \sum\limits_{i = 1}^N {\left| {{y_i} - {F_{m - 1}}\left( {{{\bf{x}}_i}} \right) - \rho h\left( {{{\bf{x}}_i};{{\bf{a}}_m}} \right)} \right|} \cr
& {\kern 1pt} \;\;\;\; = \arg \mathop {\min }\limits_\rho \sum\limits_{i = 1}^N {\left| {h\left( {{{\bf{x}}_i};{{\bf{a}}_m}} \right)} \right| \cdot \left| {{{{y_i} - {F_{m - 1}}\left( {{{\bf{x}}_i}} \right)} \over {h\left( {{{\bf{x}}_i};{{\bf{a}}_m}} \right)}} - \rho } \right|} \cr
& \;\;\;\;{\rm{ = media}}{{\rm{n}}_W}\left\{ {{{{y_i} - {F_{m - 1}}\left( {{{\bf{x}}_i}} \right)} \over {h\left( {{{\bf{x}}_i};{{\bf{a}}_m}} \right)}}} \right\}_1^N,{w_i} = \left| {h\left( {{{\bf{x}}_i};{{\bf{a}}_m}} \right)} \right|. \cr} $$
$media{n_W}\left\{ {} \right\}$表示先进行$w_i$加权,在得到的结果中,取得中位数。我们在GB过程中,采用上面的pseudore-response和$h({\bf x};{\bf a})$、以及步长$\rho_m$,可以得到loss function为LAD的GB算法。
用于回归的GBDT
上面介绍了GB方法中的LS和LAD,如果使用树模型例如CART树作为$h({\bf x};{\bf a})$,可以表述如下:$$h\left( {{\bf{x}};\left\{ {{b_j},{R_j}} \right\}_1^J} \right) = \sum\limits_{j = 1}^J {{b_j}1\left( {{\bf{x}} \in {R_j}} \right)} $$
$\left\{ {{R_j}} \right\}_1^J$表示从观测数据$\bf x$中生成的不联通区域,由树的分裂节点进行划分。而$$1\left( \cdot \right)$$,表示事件$x \in R_j$是否发生,判断样本点落在某个分支。树的参数有两部分,节点系数为$\left\{ {{b_j}} \right\}_1^J$、节点(包含选择哪个节点和确认它进行分裂的值)。回归树的更新公式为:
$${F_m}\left( {\bf{x}} \right) = {F_{m - 1}}\left( {\bf{x}} \right) + {\rho _m}\sum\limits_{j = 1}^J {{b_{jm}}1\left( {{\bf{x}} \in {R_{jm}}} \right)} --(1)$$
这里$\left\{ {{R_{jm}}} \right\}_1^J$表示第$m$轮迭代中树的节点所划分的区域。若对于loss function为最小均方差(LS),这些区域的累加用来表示当前的pseudo-response,$\left\{ {{b_{jm}}} \right\}$为最小均方差的系数:
$$b_{jm}=ave_{{\bf x}_i \in R_{jm}}{\tilde y}_i$$。步长$\rho_m$同上述一致,可以线搜索进行求解。
作者提供了一种简化方式,记${\gamma _{jm}} = {\rho _m}{b_{jm}}$。$(1)$式变化如下:
$${F_m}\left( {\bf{x}} \right) = {F_{m - 1}}\left( {\bf{x}} \right) + \sum\limits_{j = 1}^J {{\gamma _{jm}}1\left( {{\bf{x}} \in {R_{jm}}} \right)} $$
从上面公式出发,我们可以视作每级增加$J$个不同的基函数。对这样的式子,我们可以通过优化下面这个式子得到函数参数:$$\left\{ {{\gamma _{jm}}} \right\}_1^J = \arg \mathop {\min }\limits_{\left\{ {{\gamma _j}} \right\}_1^J} \sum\limits_{i = 1}^N {L\left( {{y_i},{F_{m - 1}}\left( {{{\bf{x}}_i}} \right) + \sum\limits_{j = 1}^J {{\gamma _j}1\left( {{\bf{x}} \in {R_{jm}}} \right)} } \right)} $$
因为基函数代表的每个区域之间不相互依赖,对于每一级可以拆开视为$j$个最小单位的优化:$${\gamma _{jm}} = \arg \mathop {\min }\limits_\gamma \sum\limits_{{\bf x}_i \in R_{jm}}^N {L\left( {{y_i},{F_{m - 1}}\left( {{{\bf{x}}_i}} \right) + \gamma } \right)} --(2)$$
给定当前的函数逼近$F_{m-1}(x)$在每个节点划分的区域上优化,在LAD的loss function下$(2)$可以演变为:$${\gamma _{jm}} = media{n_{{{\bf{x}}_i} \in {R_{jm}}}}\left\{ {{y_i} - {F_{m - 1}}\left( {{{\bf{x}}_i}} \right)} \right\}$$。第$m$轮第$j$节点参数$\gamma$可以表示为残差的中位数。在每一轮迭代中回归树预测当前残差的中位数。
$$\eqalign{
& {F_0}\left( {\bf{x}} \right) = median\left\{ {{y_i}} \right\}_1^N \cr
& For\;m = 1\;to\;M\;do: \cr
& \;\;\;\;{{\tilde y}_i} = {\mathop{\rm sign}\nolimits} \left( {{y_i} - {F_{m - 1}}\left( {{{\bf{x}}_i}} \right)} \right),i = 1,N \cr
& \;\;\;\;\left\{ {{R_{jm}}} \right\}_1^J = J - node\;tree\left( {\left\{ {{{\tilde y}_i},{{\bf{x}}_i}} \right\}_1^N} \right) \cr
& \;\;\;\;{\gamma _{jm}} = media{n_{{{\bf{x}}_i} \in {R_{jm}}}}\left\{ {{y_i} - {F_{m - 1}}\left( {{{\bf{x}}_i}} \right)} \right\},j = 1,J \cr
& \;\;\;\;{F_m}\left( {\bf{x}} \right) = {F_{m - 1}}\left( {\bf{x}} \right) + \sum\limits_{j = 1}^J {{\gamma _{jm}}1\left( {{\bf{x}} \in {R_{jm}}} \right)} \cr
& endFor \cr} $$
LAD只用了变量的顺序信息,pseudo-response只有$\{-1,1\}$二值,算法鲁棒性强(按,中位数其实挺难计算的,见附录思考3)如果loss function是最小均方误差LS的话,那么根据$(2)$式进行求导,可得$\gamma$更新公式。
再介绍一种更直接的思路,训练一棵树$tree$直接拟合LAD的loss。
$$tre{e_m}\left( {\bf{x}} \right) = \arg \mathop {\min }\limits_{J - node\;tree} \sum\limits_{i = 1}^N {\left| {{y_i} - {F_{m - 1}}\left( {{{\bf{x}}_i}} \right) - tree\left( {{{\bf{x}}_i}} \right)} \right|} $$
$${F_m}\left( {\bf{x}} \right) = {F_{m - 1}}\left( {\bf{x}} \right)+tree_{m}({\bf x})$$
M-Regression(Huber loss function)
M-Regression增强模型对长尾的误差分布的鲁棒性,同时保持对正太分布误差计算的高效率。
待理解”M-regression techniques attempt resistance to longtailed error distributions and outliers while maintaining high efficiency for normally distributed errors”
给出下面的Huber loss function:
$$L\left( {y,F} \right) = \left\{ {\matrix{
{{1 \over 2}{{\left( {y - F} \right)}^2},\left| {y - F} \right| < \delta } \cr
{\delta \left( {\left| {y - F} \right| - {\delta \over 2}} \right),\left| {y - F} \right| > \delta } \cr
} } \right.$$
按前述GB框架,先求pseudore-response:
$$\eqalign{
& {{\tilde y}_i} = - {\left[ {{{\partial L\left( {{y_i},F\left( {{{\bf{x}}_i}} \right)} \right)} \over {\partial F\left( {{{\bf{x}}_i}} \right)}}} \right]_{F\left( {\bf{x}} \right) = {F_{m - 1}}\left( {\bf{x}} \right)}} \cr
& \;\;\;\; = \left\{ {\matrix{
{{y_i} - {F_{m - 1}}\left( {{{\bf{x}}_i}} \right),\;\;\;\;\left| {{y_i} - {F_{m - 1}}\left( {{{\bf{x}}_i}} \right)} \right| \le \delta } \cr
{\delta \cdot {\mathop{\rm sign}\nolimits} \left( {{y_i} - {F_{m - 1}}\left( {{{\bf{x}}_i}} \right)} \right),\;\;\left| {{y_i} - {F_{m - 1}}\left( {{{\bf{x}}_i}} \right)} \right| \le \delta } \cr } } \right. \cr} $$
根据pseudo-response拟合$h({\bf x}; {\bf a})$:
$${\rho _m} = \arg \mathop {\min }\limits_\rho \sum\limits_{i = 1}^N {L\left( {{y_i},{F_{m - 1}}\left( {{{\bf{x}}_i}} \right) + \rho h\left( {{{\bf{x}}_i};{{\bf{a}}_m}} \right)} \right)} $$
关于Huber 函数具体细节参看引文[2],$\delta$定义了残差里面哪部分属于outlier,这部分使用LAD约束,其他则使用LS损失函数约束。真实的$\delta$应由$y-F^*({\bf x})$决定,其中$F^*({\bf x})$由目标函数决定。实践中通常使用$|y-F^*(x)|$分布的$\alpha$-分位数的取值:
$${\delta _m} = quantil{e_\alpha }\left\{ {\left| {{y_i} - {F_{m - 1}}\left( {{{\bf{x}}_i}} \right)} \right|} \right\}_1^N$$
关于中位数的猜想见附录思考4。
得到第$M$轮的pseudo-response之后我们用一颗回归树进行拟合。在第$j$个节点$R_{jm}$,Huber loss关于公式$(2)$的解可以一步标准迭代过程进行近似。先得到节点$R_{jm}$上残差$\{r_{m-1}({\bf x}_i)\}^N_i$中位数:
$${{\tilde r}_{jm}} = media{n_{{{\bf{x}}_i} \in {R_{jm}}}}\left\{ {{r_{m - 1}}\left( {{{\bf{x}}_i}} \right)} \right\}$$
其中${r_{m - 1}}\left( {{{\bf{x}}_i}} \right) = {y_i} - {F_{m - 1}}\left( {{{\bf{x}}_i}} \right)$。近似方法如下:
$${\gamma _{jm}} = {{\tilde r}_{jm}} + {1 \over {{N_{jm}}}}\sum\limits_{{{\bf{x}}_i} \in {R_{jm}}}^{} {{\mathop{\rm sign}\nolimits} \left( {{r_{m - 1}}\left( {{{\bf{x}}_i}} \right) - {{\tilde r}_{jm}}} \right)} \cdot \min \left( {{\delta _m},abs\left( {{r_{m - 1}}\left( {{{\bf{x}}_i}} \right) - {{\tilde r}_{jm}}} \right)} \right)$$
其中,$N_{jm}$为第$j$节点上观测值总数。有了$\gamma_{jm}$我们可以根据GBDT框架写出流程:
$$\eqalign{
& {F_0}\left( {\bf{x}} \right) = median\left\{ {{y_i}} \right\}_1^N \cr
& For\;m = 1\;to\;M\;do: \cr
& \;\;\;\;{r_{m - 1}}\left( {{{\bf{x}}_i}} \right) = {y_i} - {F_{m - 1}}\left( {{{\bf{x}}_i}} \right),i = 1,N \cr
& \;\;\;\;{\delta _m} = quantil{e_\alpha }\left\{ {\left| {{r_{m - 1}}\left( {{{\bf{x}}_i}} \right)} \right|} \right\}_1^N \cr
& \;\;\;\;{{\tilde y}_i} = \left\{ {\matrix{
{{r_{m - 1}}\left( {{{\bf{x}}_i}} \right),\;\;\;\;\left| {{r_{m - 1}}\left( {{{\bf{x}}_i}} \right)} \right| \le {\delta _m}} \cr
{{\delta _m} \cdot {\mathop{\rm sign}\nolimits} \left( {{r_{m - 1}}\left( {{{\bf{x}}_i}} \right)} \right),\left| {{r_{m - 1}}\left( {{{\bf{x}}_i}} \right)} \right| > {\delta _m}} \cr
} } \right.,i = 1,N \cr
& \;\;\;\;\left\{ {{R_{jm}}} \right\}_1^J = J - node\;tree\left( {\left\{ {{{\tilde y}_i},{{\bf{x}}_i}} \right\}_1^N} \right) \cr
& \;\;\;\;{{\tilde r}_{jm}} = media{n_{{{\bf{x}}_i} \in {R_{jm}}}}\left\{ {{r_{m - 1}}\left( {{{\bf{x}}_i}} \right)} \right\},j = 1,J \cr
& \;\;\;\;{\gamma _{jm}} = {{\tilde r}_{jm}} + {1 \over {{N_{jm}}}}\sum\limits_{}^{} {{\mathop{\rm sign}\nolimits} \left( {{r_{m - 1}}\left( {{x_i}} \right) - {{\tilde r}_{jm}}} \right) \cdot \min \left( {{\delta _m},abs\left( {{r_{m - 1}}\left( {{x_i}} \right) - {{\tilde r}_{jm}}} \right)} \right)} \cr
& \;\;\;\;\;\;\;\;j = 1,N \cr
& \;\;\;\;{F_m}\left( {\bf{x}} \right) = {F_{m - 1}}\left( {\bf{x}} \right) + \sum\limits_{j = 1}^J {{\gamma _{jm}}1\left( {{\bf{x}} \in {R_{jm}}} \right)} \cr
& endFor \cr} $$
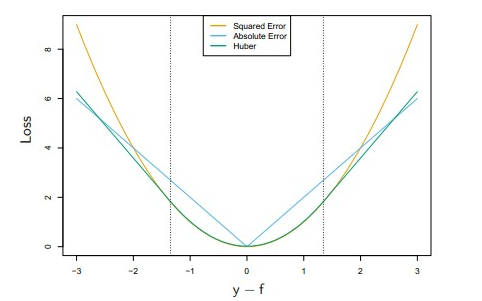
下图绘制了LS、LAD、huber的LOSS曲线,可以看到以$\delta$为分界点,中间呈现LS的性质,两边呈现LAD的线性。
下面介绍GBDT用于分类问题:
GBDT用于二分类
如何用GB方式解决二分类问题。我们首先定义loss function为负二元log似然函数(negative binomial log-liklihood):
$$L(y,F)=log(1+exp(-2yF)), y \in \{-1, 1\}$$
其中$$F\left( {\bf{x}} \right) = {1 \over 2}\log \left[ {{{\Pr \left( {y = 1|{\bf{x}}} \right)} \over {\Pr \left( {y = - 1|{\bf{x}}} \right)}}} \right]--(3)$$
有了loss function可以进一步得到pseudo-responce
$${y_i} = - {\left[ {{{\partial L\left( {{y_i},F\left( {{{\bf{x}}_i}} \right)} \right)} \over {\partial F\left( {{{\bf{x}}_i}} \right)}}} \right]_{F\left( {\bf{x}} \right) = {F_{m - 1}}\left( {\bf{x}} \right)}} = {{2{y_i}} \over {1 + \exp \left( {2{y_i}{F_{m - 1}}\left( {{{\bf{x}}_i}} \right)} \right)}}$$
步长通过线搜索得到:
$${\rho _m} = \arg \mathop {\min }\limits_\rho \sum\limits_{i = 1}^N {\log \left( {1 + \exp \left( { - 2{y_i}\left( {{F_{m - 1}}\left( {{{\bf{x}}_i}} \right) + \rho h\left( {{{\bf{x}}_i};{{\bf{a}}_m}} \right)} \right)} \right)} \right)} $$
对于GBDT,我们用树模型作为${h\left( {{{\bf{x}}_i};{{\bf{a}}_m}} \right)}$。和回归问题的处理类似,我们可以得到每个节点$R_{jm}$上的更新规则:
$${\gamma _{jm}} = \arg \mathop {\min }\limits_\gamma \sum\limits_{{{\bf{x}}_i} \in {R_{jm}}}^{} {\log \left( {1 + \exp \left( { - 2{y_i}\left( {{F_{m - 1}}\left( {{{\bf{x}}_i}} \right) + \gamma } \right)} \right)} \right)} -- (4)$$
公式$(4)$没有闭式解,我们通过单步拟牛顿法进行近似:
$${\gamma _{jm}} = \sum\limits_{{{\bf{x}}_i} \in {R_{jm}}} {{{{{\tilde y}_i}} \over {\sum\limits_{{{\bf{x}}_i} \in {R_{jm}}} {\left| {{{\tilde y}_i}} \right|\left( {2 - \left| {{{\tilde y}_i}} \right|} \right)} }}} $$
这里的${\tilde y}_i$为pseudo-response。算法流程为:
$$\eqalign{
& {F_0}\left( {\bf{x}} \right) = {1 \over 2}\log {{1 + \bar y} \over {1 - \bar y}} \cr
& For\;m = 1\;to\;M\;do: \cr
& \;\;\;\;{{\tilde y}_i} = {{2{y_i}} \over {1 + \exp \left( {2{y_i}{F_{m - 1}}\left( {{{\bf{x}}_i}} \right)} \right)}},i = 1,N \cr
& \;\;\;\;\left\{ {{R_{jm}}} \right\}_1^J = J - tree\left( {\left\{ {{{\tilde y}_i},{{\bf{x}}_i}} \right\}_1^N} \right) \cr
& \;\;\;\;{\gamma _{jm}} = \sum\limits_{{{\bf{x}}_i} \in {R_{jm}}}^{} {{{{{\tilde y}_i}} \over {\sum\limits_{{{\bf{x}}_i} \in {R_{jm}}} {\left| {{{\tilde y}_i}} \right|\left( {2 - \left| {{{\tilde y}_i}} \right|} \right)} }}} ,j = 1,J \cr
& \;\;\;\;{F_m}\left( {\bf{x}} \right) = {F_{m - 1}}\left( {\bf{x}} \right) + \sum\limits_{j = 1}^J {{\gamma _{jm}}1\left( {{\bf{x}} \in {R_{jm}}} \right)} \cr
& end\;For \cr} $$
得到最终的$F_m({\bf x})$为$F({\bf x})$的近似,$F({\bf x})$为:
$$F\left( {\bf{x}} \right) = {1 \over 2}\log \left[ {{{\Pr \left( {y = 1|{\bf{x}}} \right)} \over {\Pr \left( {y = - 1|{\bf{x}}} \right)}}} \right]--(3)$$
来了一个新样本$x_j$,若$F_m({x_j})>0$,则$y=1$,反之则$y=-1$。
根据$(3)$式,我们可以计算得到分属不同类别的概率:
$${p_ + }\left( {\bf{x}} \right) = \tilde Pr\left( {y = 1|{\bf{x}}} \right) = {1 \over {1 + \exp \left( { - 2{F_M}\left( {\bf{x}} \right)} \right)}}$$
$${p_ - }\left( {\bf{x}} \right) = \tilde Pr\left( {y = - 1|{\bf{x}}} \right) = {1 \over {1 + \exp \left( {2{F_M}\left( {\bf{x}} \right)} \right)}}$$
可以根据不同的应用,进行调权:
$$\tilde y\left( {\bf{x}} \right) = 2 \cdot 1\left( {c\left( { - 1,1} \right){p_ + }\left( {\bf{x}} \right) > c\left( {1, - 1} \right){p_ - }\left( {\bf{x}} \right)} \right) - 1$$
其中${c\left( {\tilde y, y} \right)}$为将$y$识别成$\tilde y$的cost。
剪枝
GB框架解决二分类问题的loss function在第m轮迭代中如下:
$${\phi _m}\left( {\rho ,{\bf{a}}} \right) = \sum\limits_{i = 1}^N {\log \left[ {1 + \exp \left( { - 2{y_i}{F_{m - 1}}\left( {{{\bf{x}}_i}} \right)} \right) \cdot \exp \left( { - 2{y_i}\rho h\left( {{{\bf{x}}_i};{\bf{a}}} \right)} \right)} \right]} $$
随着迭代继续,${{y_i}{F_{m - 1}}\left( {{{\bf{x}}_i}} \right)}$会变成很大,使得结果不再受新的样本影响。也就是说,当${{y_i}{F_{m - 1}}\left( {{{\bf{x}}_i}} \right)}$很大,$ \exp \left( { - 2{y_i}{F_{m - 1}}\left( {{{\bf{x}}_i}} \right)} \right)$会相对很小。
视其为权重${w_i} = \exp \left( { - 2{y_i}{F_{m - 1}}\left( {{{\bf{x}}_i}} \right)} \right)$,作为第$i$个数据的影响力。
剪枝的做法是将权重$w_i \le w_{l(\alpha)}$,其中$l(\alpha)$为下式的解:
$$\sum\limits_{i = 1}^{l\left( \alpha \right)} {{w_{\left( i \right)}}} = \alpha \sum\limits_{i = 1}^N {{w_i}} $$
通常$\alpha \in [0.05, 0.2]$,这里的剪枝和AdaBoost的”weight trimming”是一样的。将近90%到95%的样本候选被剪枝,带来10%到20%的计算速度提升。下面介绍GBDT用于多分类问题。
GBDT用于多分类
对于 $K$-类问题,同样定义loss function是
$$L\left( {\left\{ {{y_k},{F_k}\left( {\bf{x}} \right)} \right\}_1^K} \right) = - \sum\limits_{k = 1}^K {{y_k}\log {p_k}\left( {\bf{x}} \right)}--(4) $$
其中,$y_k=1(class=k) \in \{0, 1\}$,$p_k({\bf x})=Pr(y_k=1|{\bf x})$,
$${p_k}\left( {\bf{x}} \right) = {{\exp \left( {{F_k}\left( {\bf{x}} \right)} \right)} \over {\sum\limits_{l = 1}^K {\exp \left( {{F_k}\left( {\bf{x}} \right)} \right)} }} -- (5)$$
$${F_k}\left( {\bf{x}} \right) = \log {p_k}\left( {\bf{x}} \right) - {1 \over K}\sum\limits_{l = 1}^K {\log {p_l}\left( {\bf{x}} \right)} --(6)$$
$(5)$、$(6)$是等价。
将$(6)$带入到$(4)$,求一阶导可得:
$${{\tilde y}_{ik}} = - {\left[ {{{\partial L\left( {\left\{ {{y_{il}},{F_l}\left( {{{\bf{x}}_i}} \right)} \right\}_{l = 1}^K} \right)} \over {\partial {F_k}\left( {{{\bf{x}}_i}} \right)}}} \right]_{\left\{ {{F_l}\left( {\bf{x}} \right) = {F_{l,m - 1}}\left( {\bf{x}} \right)} \right\}_1^K}} = {y_{ik}} - {p_{k,m - 1}}\left( {{{\bf{x}}_i}} \right)$$
其中,$p_{k,m-1}$从$F_{k,m-1}(x)$的函数$(5)$导出。第$m$轮用K棵trees预测对应每类的残差,每棵树有$J$个节点,记作$\{R_{jkm}\}^J_{j=1}$。模型的参数$\gamma _{jkm}$更新规则:
$$\left\{ {{\gamma _{jkm}}} \right\} = \arg \mathop {\min }\limits_{\left\{ {{\gamma _{jk}}} \right\}} \sum\limits_{i = 1}^N {\sum\limits_{k = 1}^N {\phi \left( {{y_{ik}},{F_{k,m - 1}}\left( {{{\bf{x}}_i}} \right) + \sum\limits_{j = 1}^J {{\gamma _{jk}}1\left( {{{\bf{x}}_i} \in {R_{jm}}} \right)} } \right)} } (7)$$
其中,$\phi \left( {{y_k},{F_k}} \right) = - {y_k}\log {p_k}$,${F_k}\left( {\bf{x}} \right) = \log {p_k}\left( {\bf{x}} \right) - {1 \over K}\sum\limits_{l = 1}^K {\log {p_l}\left( {\bf{x}} \right)} $。$(7)$无闭式解,可以通过单步Newton-Raphson使用一个对角矩阵近似Hessian矩阵。
$${\gamma _{jkm}} = {{K - 1} \over K}{{\sum\limits_{{{\bf{x}}_i} \in {R_{jkm}}}^{} {{{\tilde y}_{ik}}} } \over {\sum\limits_{{{\bf{x}}_i} \in {R_{jkm}}}^{} {\left| {{{\tilde y}_{ik}}} \right|\left( {1 - \left| {{{\tilde y}_{ik}}} \right|} \right)} }}$$
这样我们可以构建出$K$类别的logistic GBDT框架如下:
$$\eqalign{
& {F_{k0}}\left( {\bf{x}} \right) = 0,k = 1,K \cr
& For\;m = 1\;to\;M\;do: \cr
& \;\;\;\;{p_k}\left( {\bf{x}} \right) = {{\exp \left( {{F_k}\left( {\bf{x}} \right)} \right)} \over {\sum\limits_{l = 1}^K {\exp \left( {{F_l}\left( {\bf{x}} \right)} \right)} }},k = 1,K \cr
& \;\;\;\;For\;k = 1\;to\;K\;do: \cr
& \;\;\;\;\left\{ {{R_{jkm}}} \right\}_{j = 1}^J = J - tree\left( {\left\{ {{{\tilde y}_{ik}},{{\bf{x}}_i}} \right\}_1^N} \right) \cr
& \;\;\;\;{\gamma _{jkm}} = {{K - 1} \over K}{{\sum\limits_{{x_i} \in {R_{jkm}}} {{{\tilde y}_{ik}}} } \over {\sum\limits_{{{\bf{x}}_i} \in {R_{jkm}}} {\left| {{{\tilde y}_{ik}}} \right|\left( {1 - \left| {{{\tilde y}_{ik}}} \right|} \right)} }},j = 1,J \cr
& \;\;\;\;{F_{km}}\left( {\bf{x}} \right) = {F_{k,m - 1}}\left( {\bf{x}} \right) + \sum\limits_{j = 1}^J {{\gamma _{jkm}}1\left( {{\bf{x}} \in {R_{jkm}}} \right)} \cr
& \;\;\;\;endFor \cr
& endFor \cr} $$
预测和二分类问题类似,我们得到$\left\{ {{F_{km}}\left( {\bf{x}} \right)} \right\}_1^K$可以用于预估$\left\{ {{p_{km}}\left( {\bf{x}} \right)} \right\}_1^K$。类别预测结果为:$${\hat k}\left( {\bf{x}} \right) = \arg \mathop {\min }\limits_{1 \le k \le K} \sum\limits_{k' = 1}^K {c\left( {k,k'} \right)} {p_{k'M}}\left( {\bf{x}} \right)$$
$c(k,k')$表示真实label($k'$)预测为predict($k$)的cost。
对于$p_{k'M}\left( {\bf{x}} \right)$为样本$\bf x$预测为$k$类的概率。而${\hat k}(x)$的$argmin$不太好理解。如果是求最终cost的话,能理解。但是对于前面介绍过的二分类标签的判断公式,似乎有难通顺的地方,是不是这里的比较部分应该是小于号$<$?:
$$\tilde y\left( {\bf{x}} \right) = 2 \cdot 1\left( {c\left( { - 1,1} \right){p_ + }\left( {\bf{x}} \right) > c\left( {1, - 1} \right){p_ - }\left( {\bf{x}} \right)} \right) - 1$$
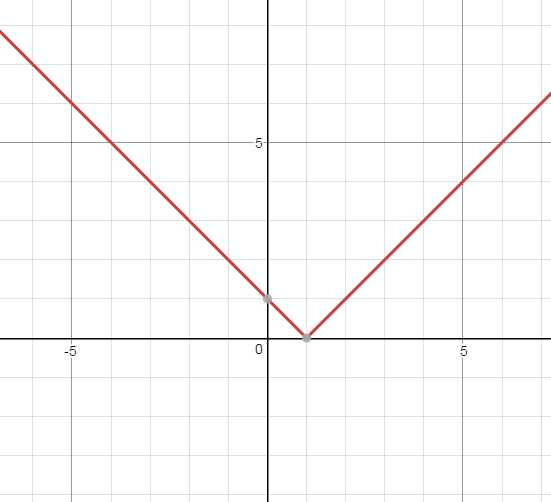
- 思考:最小绝对值偏差的导数为什么是sign(y-F) 下面图为|1-x|的曲线,导数为分段函数,值域为{-1,+1}
- 思考:LAD (least absolut deviation)的拟合H(x;a, $\rho$)中$\rho$为何是中位数。
H(X; a)为符号函数,而对于$\sum\nolimits_i {\left| {{y_i} - \rho } \right|} $,最优解为$median_y$ - 思考: 最小绝对误差的均值比LAD里偏差的中位数更容易计算。LAD里偏差的中位数更鲁棒。
- 思考:M-regression[huber]的$\alpha$分位数是什么概念
猜想配合前面loss function定义这里应该是用的双侧分位数。$\alpha$-双侧分位数的定义:当随机变量$X$的分布函数为 $F(x)$,$0 \lt \alpha \lt 1$,$\alpha$分位数是使$P\{X \lt \delta\}=F(X)=0.5\alpha$ &$P\{X > \delta\}=F(X)=0.5\alpha$。假定我们令$\alpha=0.2$,那么我们将对$\delta$满足$P\{X \lt \delta\}<0.1$&$p\{x> \delta\}<0.1$的样本使用 - 思考:GBDT和ADAboost什么关系:参看引文[1]第14页
- 正则化,在每次迭代过程中增加一个学习率参数:$${F_m}\left( {\bf{x}} \right) = {F_{m - 1}}\left( {\bf{x}} \right) + v \cdot {\rho _m}h\left( {{\bf{x}};{{\bf{a}}_m}} \right),\;\;0 < v \le 1$$
引文:
[1] Friedman J H. Greedy Function Approximation: A Gradient Boosting Machine[J]. Annals of Statistics, 2000, 29(5):1189–1232.
[2]Huber, P. (1964). Robust estimation ofa location parameter. Ann. Math. Statist. 35 73–101.
[3]Friedman J, Tibshirani R. Special Invited Paper. Additive Logistic Regression: A Statistical View of Boosting: Discussion[J]. Annals of Statistics, 2000, 28(2):pages. 374-376.
ShawnXiao@baidu