XGboost核心源码阅读
上篇《xgboost: A Scalable Tree Boosting System论文及源码导读》介绍了xgboost的框架和代码结构。本篇将继续讨论代码细节,可能比较枯燥,坚持一下哈。
接下来按这个顺序整理笔记,介绍xgboost的核心代码:
- 树的结构如何?
- 树的操作有哪些?
主要包括:怎么生成一棵树? 何时,且如何进行剪枝?什么时候进行数据采样,怎么采样? 分布式并行怎么完成?
上面这2个问题是寻求实现具体算法的思考过程,笔者也在一边读一边记录,有理解错谬的地方请指出。
树的结构如何?
从代码的UML图可以看到RegTree派生自TreeModel类,TreeModel类中定义了子类Node,结构如下: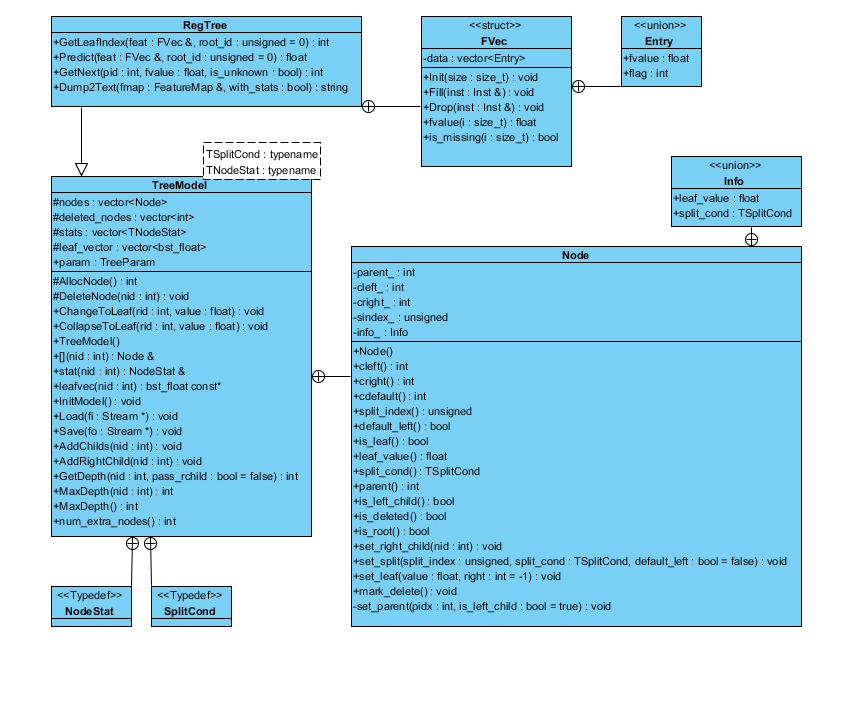
从代码角度介绍两个重要的数据结构TreeModel
而Node具体代码为:
对于基本数据结构稍事了解之后,我们开始进入主题,也是我着手写这篇文章的目的:
怎么生成一棵树?
在前一篇博客里面比较详细涉及到xgboost的一些算法,这些不再重复叙述,这里参考了杨军[2]的介绍,按单机版结合前面介绍的代码结构图,先进行一遍代码走读:
从代码走读中可以看到,gbtree最核心处定义了ColMaker, DistColMaker, LocalHistMaker, GlobalHistMaker, HistMaker, TreePruner, TreeRefesher, SketchMaker, TreeSyncher 等多种树操作,在论文里有介绍的仅有部分。
下面逐一进行分解,看看这不同的操作实质上代表了什么动作,如何实现。
xgboost在树的操作定义使用装饰(decorator)模式[1],基类TreeUpdater为抽象构件,定义了基本接口: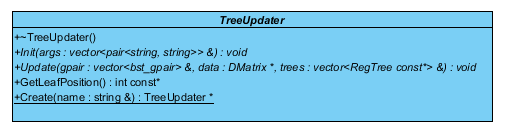
初始化init(),树的更新操作update(), 取得更新操作后叶子位置GetLeafPosition(), 产生具体构建updater的creat()函数。
ColMaker
从Updater类中派生ColMaker为具体构建类(为论文实现的单机多线程版本),主要用于实现单棵树生成,类的结构如下图。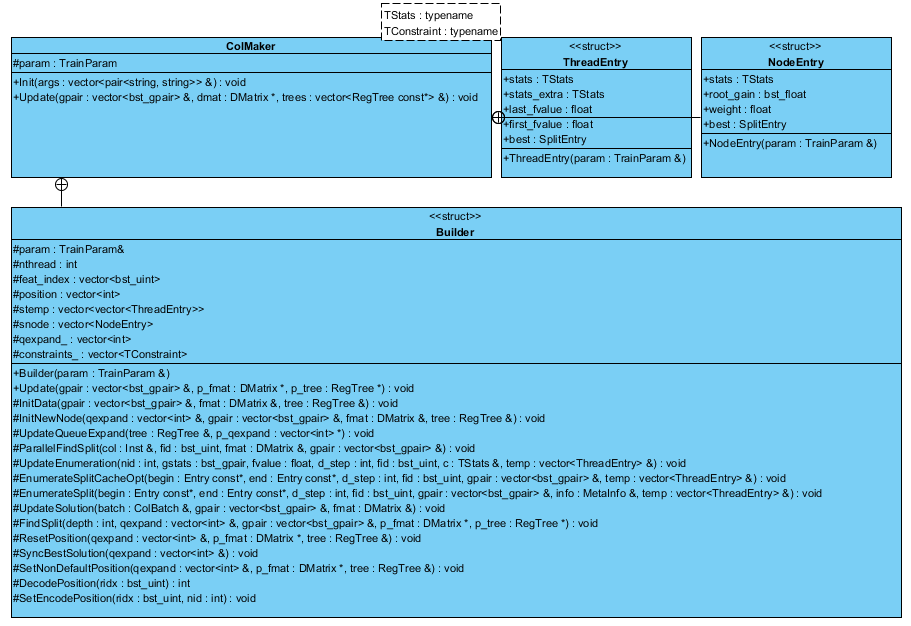
ColMaker类中最重要为树的Builder 结构体,在Builder中实现ColMaker主要算法,主要实现在Builder->Update()函数中。
下面具体介绍下Builder->Update()函数的核心代码(updater_colmaker.cc):
|
|
怎样剪枝
TreePruner (prune a tree given the statistics)
剪枝操作由TreePruner进行,对于一棵树,通过比对节点所带来的loss收益决定是否剪枝。
核心代码(updater_prune.cc)如下:
如何进行分布式?
HistMaker (use histogram counting to construct a tree)
Histgram使用直方图法近似加速建树过程,HistMaker和Colmaker一样,用于建树,不同是HistMaker并不直接由基类派生,而是HistMaker->BaseMaker->Updater,关系如图: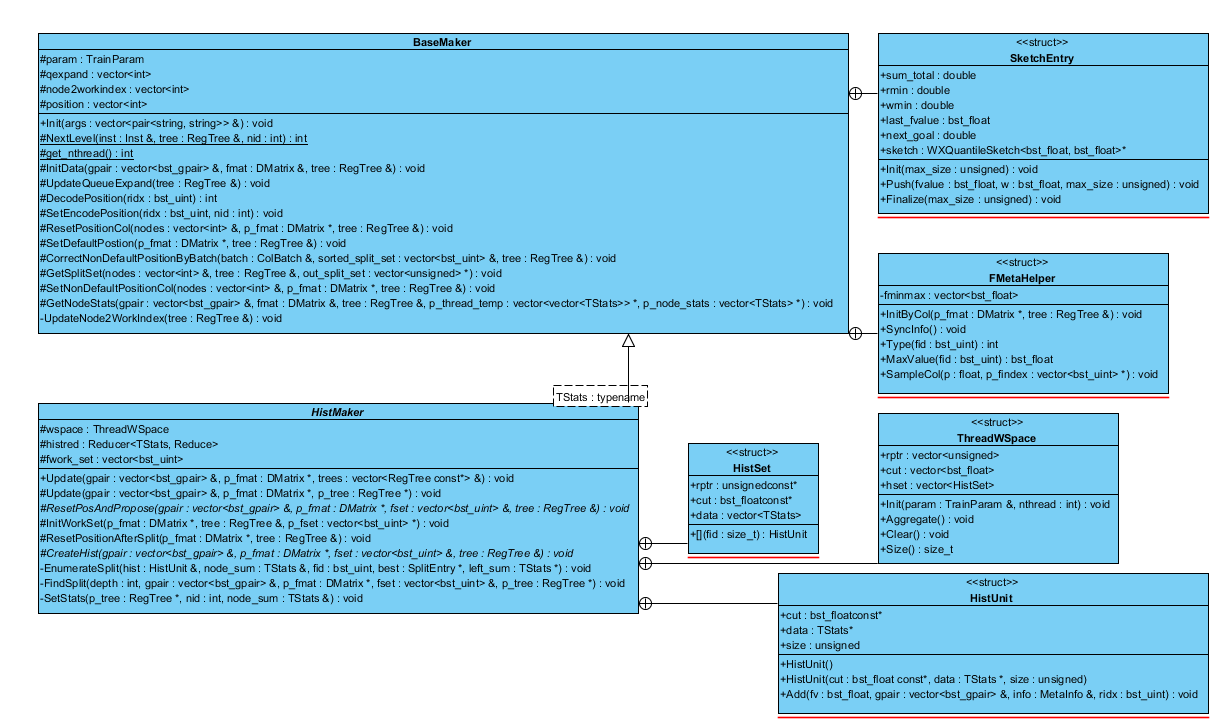
HistMaker类定义了基于直方图法的方法接口,具体的实现在CQHistMaker/QuantileHistMaker,QuantileHistMaker中调用了SketchMaker进行采样.
BaseMaker(updater_basemaker-inl.h)在Updater基类上增加了一些公共操作,后面介绍的SketchMaker也是派生于BaseMaker。按row based进行分布式建树,每台机器各自找到各自候选分割点,每一部分算出自己的统计量,用allreduce合并起来后再根据全局统计量计算最终的分割点,最终层次遍历的构建树[1]
由核心代码(Updater_histmaker.cc)走读如下:
xgboost的论文中未有提及直方图法,是树模型常用的近似方法,对统计量进行聚合统计,存储为一个个桶,然后在这些桶之间寻找最佳分裂点,为了进一步了解这种方式的建树过程,这里需要重点探索下CreatHist() 以及FindSplit(),两处函数具体的实现在派生类CQHistMaker->HistMaker,CQHistMaker实现了具体的分布式计算,在InitWorkSet()中进行机器节点的数据分片和信息同步。其类UML图如下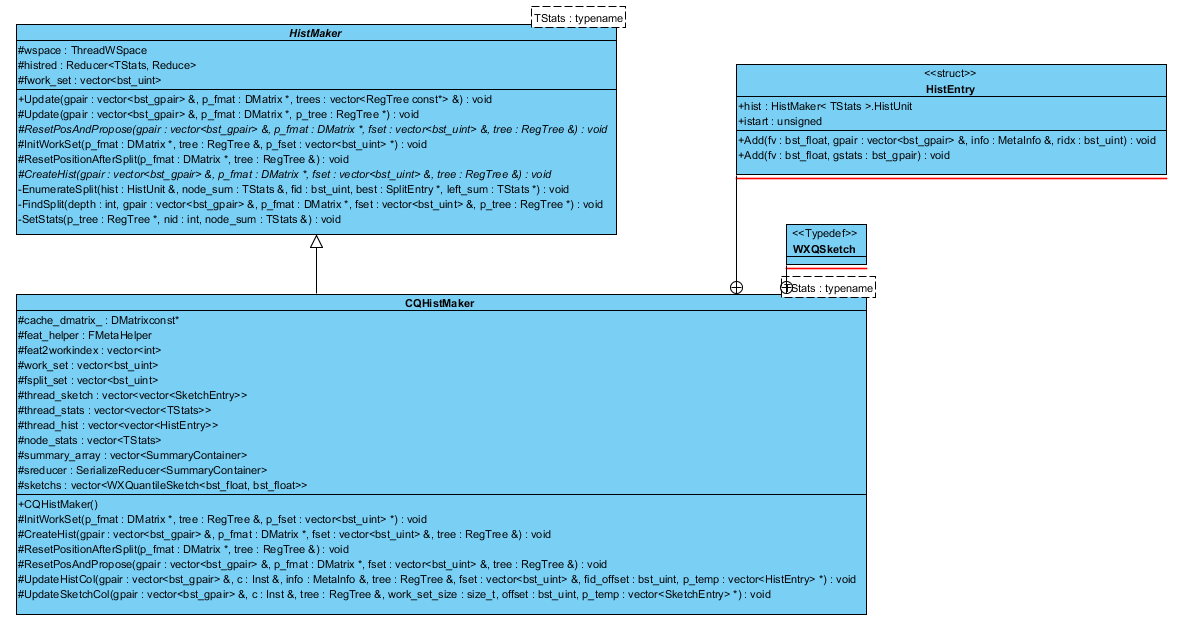
CreatHist()作用为将统计量存储于待分割节点的直方图分桶中,对CreatHist()函数进行代码走读,其分布式计算是基于RABIT实现的:
FindSplit()通过处理每个桶的特征量进行分裂点查找,代码走读如下:
近似算法怎么实现?
SketchMaker(use approximation sketch to construct a tree)
介绍SketchMaker之前,需要对此前论文导读中的加权分位数略图做少许补充。在传统的GK 算法[4]和其他扩展[5]之上,作者提出加权分位数略图算法,并引入支持merge和prune操作的数据结构进行实现。先介绍quantile summary,定义为以相对错误率$\varepsilon $返回分位数查询结果。
- merge操作:若两个summary的的相对正确率分别为$\varepsilon_1 $和$\varepsilon_2 $,将二者merge得到的新summary的相对错误率为$max \{\varepsilon_1, \varepsilon_2 \}$
- prune操作:将summary中元素个数缩减到$b+1$那么相对错误率率将从$\varepsilon$增加到$\varepsilon+{1 \over b}$。
二者如何实现,详细介绍见引文[3]附录部分《WEIGHTED QUANTILE SKETCH》。
xgboost通过不同的summary操作(WQSummary/WXQSummary/GKSummary)定义QuantileSketchTemplate类型,从而派生出不同的具体的sketch类(WQuantileSketch/WXQuantileSketch/GKQuantileSketch)。其中WXQSummary派生自WQSummary,在prune操作上效率要高些。
|
|
自此从代码角度交代了前文《xgboost: A Scalable Tree Boosting System论文及源码》的作者的具体实现思路,希望能够进一步加深对boosting方法的理解。目前最新的进展为XGBoost4J-Spark发布进一步融入Spark的应用场景中(2016/10/26)见附录[3],后续的发展会继续跟进。
PS. TreeRefresher 代码中未见引用这里不做进一步介绍。
[1]设计模式——装饰模式(Decorator), @shu_lin
[2]机器学习算法中GBDT和XGBOOST的区别有哪些?, @杨军
[3]Chen, Tianqi, and C. Guestrin. “XGBoost: A Scalable Tree Boosting System.” (2016).
[4]L. Breiman. “Random forests. Maching Learning”, 2001.
[5]Q. Zhang and W. Wang. A fast algorithm for approximate quantiles in high speed data streams. In Proceedings of the 19th International Conference on Scientic and Statistical Database Management, 2007.
附录:
[1]xgoost调参技巧:
使用TrainValidationSplit和RegressionEvaluator自动进行高度max_depth和树权重$\eta$调参。
[2]MPI Allreduce操作介绍,可结合reduce理解,reduce产生的作用示意如下图: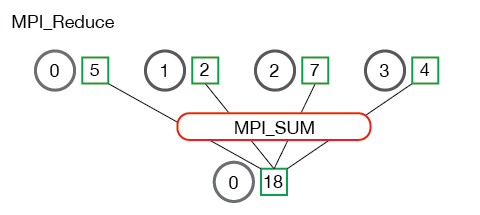
计算中需要归集所有结果,再分发到各个process中,Allreduce起这个作用,可以结合最小均方差的例子进行理解(点击链接),具体在流程中的作用如下图示意: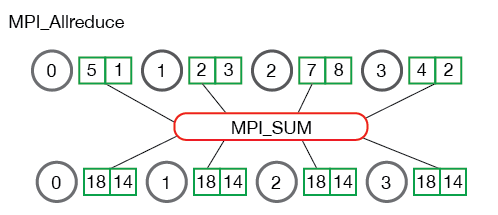
[3]XGboost与Spark的完全集成 @Nan Zhu
彩蛋:
[1]《PRML中文版》百度网盘地址, @马春鹏
写这篇博客有个痛点,代码的过度抽象和大量模板类的使用对阅读带来比较大的伤害,也是这篇文章历时许久的部分原因。如果您有好的代码阅读工具,不吝一并推荐下。
介绍下我的两款辅助软件:
Source Insight: 主司代码阅读
visual paradigm for UML 主司UML类图解析
另外,推荐百度学术的引文功能,写博客很方便
ShawnXiao@baidu