Word Embedding札记
如何利用文本的上下文信息,得到更有意义的向量表达(word embedding),是NLP领域研究的重点。本篇笔记目的在于整理词向量的发展历程,方便理解什么是词向量,怎么得到词向量。词向量也叫词的分布式表达,主要有三类方法:聚类,矩阵分解,神经网络。
基于聚类的分布表示(clusteringbased word representation)
这类方法通过聚类将词和类的标签建立关联,关联关系可以是确定性也可以是概率表示,用这种方式构建词与其上下文之间的关系。相关工作有(Brown, 1992)[10], (Ney, 1993)[35], (Niesler, 1998)[36]。布朗聚类(Brown, 1992)[10]是一种层级聚类方法,聚类结果为每个词的多层类别体系。可以根据两个词的公共类别判断这两个词的语义相似度。
基于矩阵的分布表示(distributional representation)
构建一个“词-上下文”矩阵,从矩阵中获取词的表示。在“词-上下文”矩阵中,每行对应一个词,每列表示一种不同的上下文,矩阵中的每个元素对应相关词和上下文的共现次数。
a. 矩阵构造
b. 矩阵元素值的确定
c. 降维技术将高维稀疏的向量压缩成低维稠密
典型如Latent Semantic Analysis (LSA) 的做法,构造word-doc矩阵,TF-IDF为每个元素的值。使用SVD分解,得到词的低维表达(Deerwester, 1990)[37] (Bellegarda, 1997)[34]。介绍两份比较近的工作:
- GloVe(Pennington, 2014)[27],GloVe 模型是一种对“词-词”矩阵进行分解从而得到词表示的方法。矩阵第$i$行第$j$列的值为词$v_i$与词$v_j$ 在语料中的共现次数$x_{ij}$ 的对数。在矩阵分解步骤,GloVe 模型借鉴了LSA (Deerwester,1990)[31],在计算重构误差时,只考虑共现次数非零的矩阵元素,同时对矩阵中的行和列加入了偏移项,根据共现词频对重构误差进行调权。文章论述了基于矩阵分解方法和skip-gram/ivLBL型优化目标相似,代码开源在:github,主页链接:paper。关于矩阵分解和神经网络方法之间关系的更多讨论可以参看(Omer Levy, 2014)[25], (Li Y, 2015)[26]
- FOREST(Yogatama, 2014)[32], FOREST模型和GloVe不同,”词-词”矩阵第$i$行第$j$列的元素为词$v_i$与词$v_j$的互信息,将互信息矩阵分解为基矩阵和词的表示矩阵的乘积,在目标函数中,对表示矩阵的每一个维度,引入结构化正则化项。使用在线词典学习方法进行求解。
基于神经网络的分布表示(distributed representation)
神经网络词向量表示技术通过神经网络技术对上下文,以及上下文与目标词之间的关系进行建模,这类方法的最大优势在于可以表示复杂的上下文。
发展轨迹:
- 神经网络求解二元语言模型 (徐伟,2000)[13]
- Neural Network Language Model (Yoshua Bengio, 2001, 2003)[14,15]
- Hierarchical NNLM(Bengio, 2005)[39]
- Log-Bilinear Language Model (Mnih & Hinton, 2007)[16]
- Hierarchical LBL(Mnih, 2008)[17] {注:Hierarchical Softmax}
- vector LBL / inverse vector LBL(Mnih, 2013)[18] {注:Skip-gram, 噪声比估算NCE}
- C & W model(Collobert & Weston, 2008)[21] {注:pair-wise negative sampling}
- CBOW & Skip-gram model(Mikolov,2013)[22], (Mikolov, 2013)[23]
接下来按时序介绍下上面几篇文章:
- (徐伟, 2000)[13]提出使用单层全联通神经网络处理语言模型,对词的bigram语言模型进行建模,最小化混淆度的log似然为目标,输入为每个词的one-hot表示,输出为给定当前词其他词的概率,通过softmax进行归一化输出值。
- (Bengio, 2001, 2003][14,15]提出同时训练神经网络语言模型和词向量的方法。简介下[15, Bengio, 2003]的工作,将词表示为m维的特征向量,将语言模型表示为词向量的概率函数,同时学习词的特征向量和概率函数的参数。网络结构如下图:
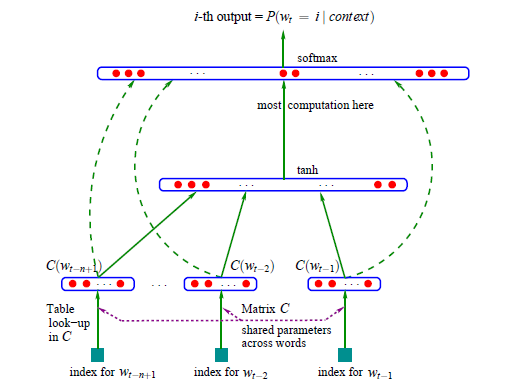
绿色虚线表示输入x有直连到softmax层,Bengio模型中这部分是可选的,因此也有其他地方的图是略掉这条虚线。直连边能让模型学习到词的权重更多,加快收敛速度。如果去除直连的话,通过隐层能学习到较多的泛化。由于激活函数和归一化部分计算耗时,论文里讨论了两种建立在异步更新权重的并行方法:共享内存的多处理器并行和网络并行。 - (Bengio, 2005)[39]提出了Hierarchical NNLM,通过词义之间的关系启发式的构建二叉树,代替归一化计算,将训练速度提升200倍。构建树的启发来自(Goodman, 2001)[40],将计算条件概率转为为一系列子分类概率的乘积,对于子分类问题,每一个分支,Bengio使用同一个分类器进行决策,由于分类的需求使得每一个叶子节点需要具备类别意义,很自然地引入了WordNet词之间的关系启发式地构建叶子节点。
- (Mnih & Hinton, 2007)[16]用RBM建模LM,提出了三个模型,分别是Factored RBM, Temporal Factored RBM和Log-Bilinear Language Model。 语言模型结构如下图:
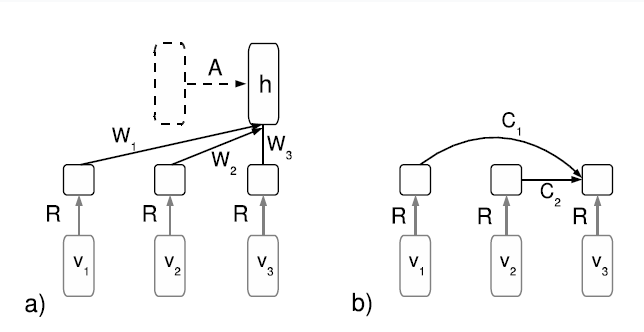
其中$ v_i $为词的index向量,$R$为特征向量表,二者相乘可得到第$i$个词的向量表达。$h$为隐层。a). 左边模型结构实线部分为Factored RBM,结合虚线框部分构成Temporal Factored RBM,虚线框表示$h_{t-1}$,b). 右边结构为Log-Bilinear Language Model。能量表达式中去除了隐层,简化网络结构,提升训练速度。三个模型都是通过Constrastiv Divergence算法(Hinton, 2002)[38]进行训练。 - (Mnih & Hinton, 2008)[17]在(Bengio, 2005)[39]的结构化NNLM启发下对LBL进行改进,提出了Hierarchical LBL。为了降低计算复杂性,限制对上下文Context的关系矩阵为对角矩阵,这种简化相当于直接进行两个向量内积。有别于引入WordNet资源,Mnih提出另一种思路建立词的二叉树结构,随机初始化二叉树,训练得到初始词向量。从根节点开始迭代使用高斯混合模型(K=2)进行聚类,为不同的词选择不同的分支。实验效果上看这种启发式建树的方式能明显提高LM的效果。
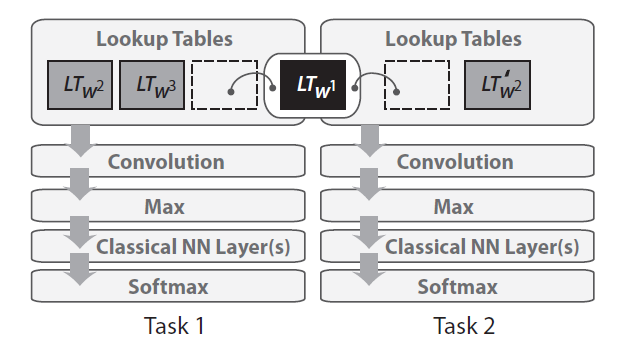
- (Collobert &Weston, 2008)[21]尝试使用一套框架完成多项任务,训练LM任务通过随机替换当前词的方式构造负例,得到判别式语言模型同时产出词向量,判别式语言模型无需进行输出概率归一化,加快了计算速度,并尝试了将语言模型结合其他序列标注任务(NER, POS, Semantic Role Labeling)同时训练的方式,各个任务共享词的向量表达。后续在这个基础上提出了SENNA model(Collobert, 2011)[28]。下图为多任务训练示意图。
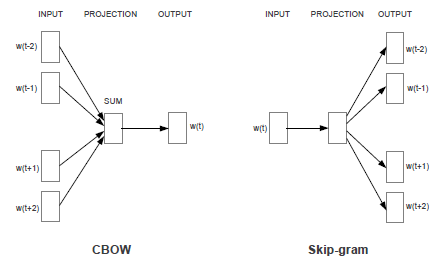
- (Mikolov, 2013)[22]提出了CBOW(Continuous Bag Of words)和skipgram模型,CBOW使用窗口上下文作为输入,预测当前词。skipgram使用当前词作为输入,预测窗口范围内的其他词,精简了隐层,计算效率大为提高。下图为CBOW和skipgram网络结构图:
- (Mnih & Kavukcuoglu, 2013)[18] 受Mikolov启发,在log-Bilinear Language Model基础上将矩阵运算简化为向量运算得到vector log-Bilinear Model(vLBL),进一步简化上下文的表达为简单求和等价于CBOW,借鉴skipgram的思想:使用当前词预测上下文,得到inverse vector log-Bilinear Model(ivLBL),目标函数采用Noise-contrastive estimation(Gutmann, 2012)[42],代替原预测目标词的概率,加快了算法的收敛。在速度上比CBOW和skipgram有了进一步改善。
- (Mikolov, 2013)[23] 在skipgram基础上尝试了NCE,并进一步简化NCE至Negative Sampling。训练过程中引入了采样(subsampling)来减轻无意义的高频词对词向量学习带来的影响。引入短语识别,解决先前词向量训练单位为unigram导致专名被打散的问题。这些特性同样可以用在CBOW模型。
上面罗列了近些年词向量技术发展的比较重要的文章,希望能帮助读者了解对词向量的发展过程。近两年也有一些比较好的工作,
a). 通过在目标函数中,引入词典中词义关系(同义词、词的上下位)进行联合训练(Yu M, 2014)[46]。
b). 引入双语语料,在不同语种的语料无监督得到词向量,利用不同语料间词对的关系进行典型相关分析(canonical correction analysis),将词向量映射到一个新的空间(Faruqui, 2014)[47]。
c). 在各模型得到的词向量基础上,引入词典资源进行增强(Faruqui M, 2014)[43]。
d). 将网络结构转为局部线性结构学习节点的embedding,根据转化方式可以分为深度优先版本DeepWalk(Perozzi, 2014)[44],广度优先版本LINE(Tang, 2015)[45]。
e). 进一步,在学习网络结构embedding的基础上引入了半监督学习,并给出了transductive框架(DeepWalk&LINE)和inductive框架。(Yang Z, 2016)[46].
如何衡量词向量的语言学特性,来博士的毕业论文(2016)[1]总结了8个评价指标
- 词义相关性(ws): WordSim353数据集,词对语义打分。
- 同义词检测(tfl): TOEFL数据集,80个单选题。准确率评价
- 单词语义类比(sem): 9000个问题。queen-king+man=women。准确率
- 单词句法类比(syn): 1W个问题。dancing-dance+predict=predicting。准确率
词向量用作特征 - 基于平均词向量的文本分类(avg): IMDB数据集,Logistic分类。准确率评价
- 命名实体识别(ner): CoNLL03数据集,作为现有系统的额外特征。F1值
词向量用作神经网络模型的初始值 - 基于卷积的文本分类(cnn): 斯坦福情感树库数据集,词向量不固定。准确率
- 词性标注(pos): 华尔街日报数据集,Collobert等人提出的NN。准确率
论文中对各模型进行了横向实验比较,推荐阅读。
word2vec源码及扩展
作者 Tomas Mikolov (Linked In) 目前在facebook
word2vec: 下载地址, 更新日志
笔者对核心代码word2vec.c进行了注释(按:可能是市面上最详lao细dao的注释),增加了两个小工具,见【github仓库】,txt2bin(明文转二进制)和distance_search(递归查找近邻向量)。
[更多扩展]对word2vec的具体实现进行优化可以参考“BIDMatch”(canny J, 2015)[48]高性能机器学习库的GPU版本,见 【github仓库】。 (Ji S, 2016)[49]将计算向量内积转为矩阵运算,使得计算从L1 level BLAS转为L3 level BLAS,并实现了分布式版本,支持增加计算节点加速词向量训练,见【github仓库】。
笔者按:本文定位为论文阅读整理笔记,前前后后历时数月。如果错漏了知识,请在评论里指出,谢谢。全文没有公式,读者如果能耐心看到这里,我会很开心。接下来会在业余时间对word2vec进行代码走读,然后在这个基础上做些词义相关的小实验,希望得到有意思的结果。
[1]基于神经网络的词和文档语义向量表示方法研究,来斯惟,中科院自动化研究所, 2016,文章地址:百度网盘
[2] Daniel D Lee and H Sebastian Seung. Algorithms for non-negative matrix actorization. In Advances in neural information processing systems, pages 556–562, 2001.
[3] Chih-Jen Lin. Projected gradient methods for nonnegative matrix factorization. Neural computation, 19(10):2756–2779, 2007.
[4] Paramveer S. Dhillon, Dean P. Foster, and Lyle H. Ungar. Multi-view learning of word embeddings via cca. In Advances in Neural Information Processing Systems, pages 199–207, 2011.
[5] Paramveer S. Dhillon, Dean P. Foster, and Lyle H. Ungar. Eigenwords: Spectral word embeddings. The Journal of Machine Learning Research, 16, 2015.
[6] Rémi Lebret and Ronan Collobert. Word embeddings through hellinger pca. EACL 2014, page 482, 2014.
[7] Thomas K Landauer, Peter W Foltz, and Darrell Laham. An introduction to latent semantic analysis. Discourse processes, 25(2-3):259–284, 1998.
[8] Jeffrey Pennington, Richard Socher, and Christopher D Manning. GloVe : Global Vectors for Word Representation. In Proceedings of the Empiricial Methods in Natural Language Processing, 2014.
[9] Fernando Pereira, Naftali Tishby, and Lillian Lee. Distributional clustering of english words. In Proceedings of the 31st annual meeting on Association for Computational Linguistics, pages 183–190, 1993.
[10] Peter F Brown, Peter V Desouza, Robert L Mercer, Vincent J Della Pietra, and Jenifer C Lai. Class-based n-gram models of natural language. Computational linguistics, 18(4):467–479, 1992.
[11] Robert M. Bell and Yehuda Koren. Lessons from the netflix prize challenge. SIGKDD Explor. Newsl., 9:75–79, 2007.
[12]Joseph Turian, Lev Ratinov, and Yoshua Bengio. Word representations: a simple and general method for semi-supervised learning.
[13] Wei Xu and Alex Rudnicky. Can artificial neural networks learn language models? In Sixth International Conference on Spoken Language Processing, 2000.
[14] Yoshua Bengio, Réjean Ducharme, and Pascal Vincent. A neural probabilistic language model. In Advances in Neural Information Processing Systems, pages 932–938, 2001.
[15] Yoshua Bengio, Réjean Ducharme, Pascal Vincent, and Christian Jauvin. A Neural Probabilistic Language Model. The Journal of Machine Learning Research, 3:1137–1155, 2003.
[16] Andriy Mnih and Geoffrey Hinton. Three new graphical models for statistical language modelling. In Proceedings of the 24th international conference on Machine learning, pages 641–648, 2007.
[17] Andriy Mnih and Geoffrey E Hinton. A scalable hierarchical distributed language model. In Advances in neural information processing systems, pages 1081–1088, 2008.
[18] Andriy Mnih and Koray Kavukcuoglu. Learning word embeddings efficiently with noise-contrastive estimation. In Advances in Neural Information Processing Systems, pages 2265–2273, 2013.
[19] Tomáš Mikolov. Statistical language models based on neural networks. PhD thesis, Brno University of Technology, 2012.
[20] Tomas Mikolov, Martin Karafiát, Lukas Burget, Jan Cernockỳ, and Sanjeev Khudanpur. Recurrent neural network based language model. In INTERSPEECH 2010, 11th Annual Conference of the International Speech Communication Association, pages 1045–1048, 2010.
[21]Ronan Collobert and Jason Weston. A unified architecture for natural language processing: Deep neural networks with multitask learning. International Conference on Machine Learning, 2008
[22]Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. International Conference on Learning Representations Workshop Track, 2013.
[23]Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pages 3111–3119, 2013
[24] Turian J, Ratinov L, Bengio Y. Word representations: a simple and general method for semi-supervised learning[C]// ACL 2010, Proceedings of the, Meeting of the Association for Computational Linguistics, July 11-16, 2010, Uppsala, Sweden. 2010:780-1.
[25] Omer Levy and Yoav Goldberg. Neural word embedding as implicit matrix factorization. In Advances in Neural Information Processing Systems, pages 2177–2185, 2014.
[26] Yitan Li, Linli Xu, Fei Tian, Liang Jiang, Xiaowei Zhong, and Enhong Chen. Word embedding revisited: A new representation learning and explicit matrix factorization perspective.
[27] Pennington J, Socher R, Manning C. Glove: Global Vectors for Word Representation[C]// Conference on Empirical Methods in Natural Language Processing. 2014.
[28]Ronan Collobert, Jason Weston, L´eon Bottou,Michael Karlen, Koray Kavukcuoglu, and Pavel Kuksa. 2011. Natural Language Processing (Almost) from Scratch. JMLR, 12:2493–2537
[29] Minh-Thang Luong, Richard Socher, and Christopher D Manning. 2013. Better word representations with recursive neural networks for morphology. CoNLL-2013
[30] Omer Levy, Yoav Goldberg, and Israel Ramat-Gan. 2014. Linguistic regularities in sparse and explicit word representations. CoNLL-2014.
[31] Scott Deerwester, Susan T. Dumais, George W. Furnas, Thomas K. Landauer, and Richard Harshman. 1990. Indexing by latent semantic analysis. Journal of the American Society for Information Science, 41.
[32] Yogatama D, Faruqui M, Dyer C, et al. Learning Word Representations with Hierarchical Sparse Coding[J]. Eprint Arxiv, 2014.
[33] Scott Deerwester, Susan T. Dumais, George W. Furnas, Thomas K. Landauer, and Richard Harshman. 1990. Indexing by latent semantic analysis. Journal of the American Society for Information Science, 41.
[34] Bellegarda J R. A latent semantic analysis framework for large-Span language modeling.[C]// European Conference on Speech Communication and Technology, Eurospeech 1997, Rhodes, Greece, September. 1997.
[35] R. Kneser and H. Ney. Improved backing-off for m-gram language modeling. In International Conference on Acoustics, Speech and Signal Processing, pages 181–184, 1995.
[36] T.R. Niesler, E.W.D. Whittaker, and P.C. Woodland. Comparison of part-of-speech and automatically derived category-based language models for speech recognition. In International Conference on Acoustics, Speech and Signal Processing, pages 177–180, 1998.
[37] Deerwester S, Dumais S T, Furnas G W, et al. Indexing by latent semantic analysis[J]. Journal of the Association for Information Science and Technology, 1990, 41(6):391-407.
[38] Hinton, G. E. (2002). Training products of experts by minimizing contrastive divergence. Neural Computation, 14, 1711–1800.
[39] FredericMorin and Yoshua Bengio. Hierarchical probabilistic neural network language model. In Robert G. Cowell and Zoubin Ghahramani, editors, AISTATS’05, pages 246–252, 2005
[40] Goodman, J. (2001b). Classes for fast maximum entropy training. In International Conference on Acoustics, Speech, and Signal Processing, Utah.
[41] M.U. Gutmann and A. Hyv¨arinen. Noise-contrastive estimation of unnormalized statistical models, with applications to natural image statistics. Journal of Machine Learning Research, 13:307–361, 2012.
[42] Gutmann M U, Hyv&#, Rinen A. Noise-contrastive estimation of unnormalized statistical models, with applications to natural image statistics[J]. Journal of Machine Learning Research, 2012, 13(1):307-361.
[43] Faruqui M, Dodge J, Jauhar S K, et al. Retrofitting Word Vectors to Semantic Lexicons[J]. Eprint Arxiv, 2014.
[44] Perozzi B, Alrfou R, Skiena S. DeepWalk: online learning of social representations[J]. Eprint Arxiv, 2014:701-710.
[45] Tang J, Qu M, Wang M, et al. LINE: Large-scale Information Network Embedding[J]. 2015.
[46] Yu M, Dredze M. Improving Lexical Embeddings with Semantic Knowledge[C]// Meeting of the Association for Computational Linguistics. 2014:545-550.
[47] Manaal Faruqui and Chris Dyer. 2014. Improving vector space word representations using multilingual correlation. In Proceedings of EACL
[48] Canny J, Zhao H, Jaros B, et al. Machine learning at the limit[C]// IEEE International Conference on Big Data. IEEE Computer Society, 2015:233-242.
[49] Ji S, Satish N, Li S, et al. Parallelizing Word2Vec in Shared and Distributed Memory[J]. 2016.
[50]Yang Z, Cohen W W, Salakhutdinov R. Revisiting Semi-Supervised Learning with Graph Embeddings[J]. 2016.
Author: ShawnXiao@baidu