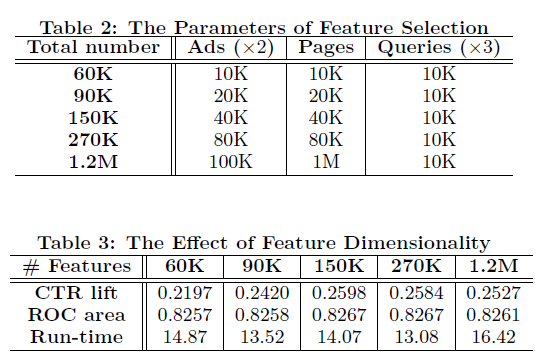
论文1:《Chinese Spelling Error Detection and Correction Based on Language Model, Pronunciation, and Shape》[1, Yu, 2013]
论文提供了一种准确较高、召回较低的纠错方法。
- Character级别 n-gram language model。
- 拼音和字形召回候选
- 词典过滤掉部分无效候选
- 取最高语言模型打分
- 高于既定阈值则认为是替换候选
系统流程图: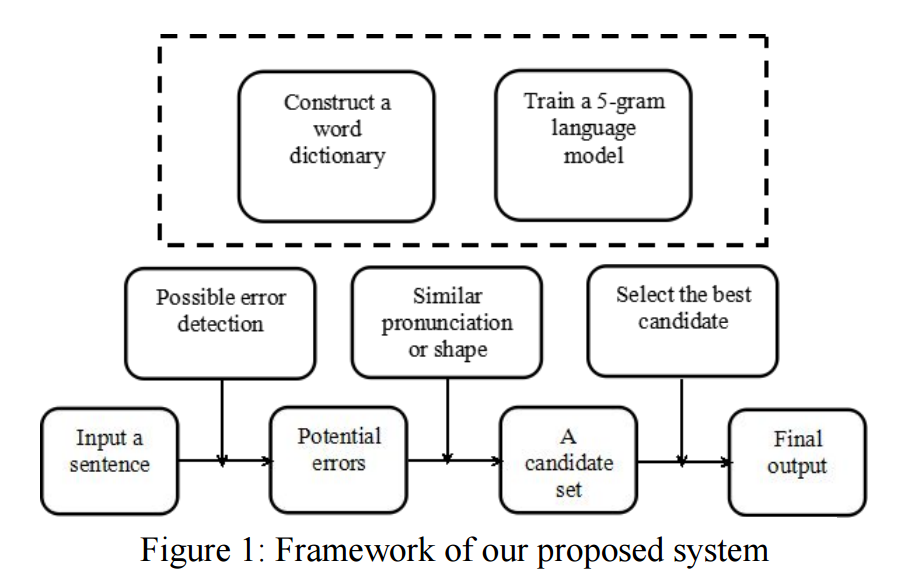
各步骤展开,具体简述如下:
- 判断何处有输入错误,两种方式:
a. 使用正向反向的character级别的ngram语言模型,对每个位置进行打分,得分低的地方标记为待纠错片段。
b. 切词切出独立的字符。
这里的ngram语言模型为5-gram,为了避免过多召回,阈值设定较为严苛。通过语言模型判断出的可疑位置将与上下文组合进行词典查词。 - 召回:上一步词典过滤出的最终可疑词进行同音字和形近字的召回。召回候选与前后近邻组合为词进行词典查词过滤出有效候选。
- 打分:候选中语言模型最高分,且得分大于阈值,则胜出。
论文2:《Guest Editorial: Special Issue on Chinese as a Foreign Language》[2, Lee, 2015]
论文为纠错综述文章,提了6篇文章,逐一拆解如下:
- 《A Unified Framework for Chinese Spelling Correction》[3]提出基于隐马尔科夫和排序模型的纠错框架,配合基于规则的模型进行汉字纠错,其数据集为CLP-2014-CSC
- 《A Study on Chinese Spelling Check Using Confusion Sets and N-gram Statistics》[4]通过说文解字和四角码扩大候选集合(Confusion Sets),结合N-gram统计进行拼写纠错。
- 《Automatically Detecting Syntactic Errors in Sentences Written by Learners of Chinese as a Foreign Language》[5]介绍了一种通过自动生成和手工规则来发现中文语法问题,提出了KNGED算法来发现语法错误。其数据集为NLP-TEA CFL(Chinese as Foreign Language)。
- 《Automatic Classification of the “De” Word Usage for Chinese as a Foreign Language》[6]聚焦在”De”音的三个常用字{的,地,得}的形态句法,提出LEM 2算法用于规则生成,基于规则进行{的,地,得}的错别字分类识别。
- 《The Error Analysis of “Le”Based on “Chinese Learner Written Corpus”》以“华语学习者语料库”为本的”了”字句错误分析。“了”为中文常见的时貌标记和句尾虚词,但其表动作完成的语义,可能使华语学习者将其泛化为过去时标记,而成为学习难点。文章以”台师大华语学习者语料库”为本,分析初级A2和中级B1英语母语者学习”了”字句时的使用情形和偏误类型,有以下发现:
- 初级A2和中级B1学习者都较难掌握作为时貌标记的”了”,这类问题最常见,而较容易掌握作为句尾虚词的”了2”。
- 不论初级A2或中级B1都有”了”过度泛化的情况。
- 此二级学习者在“了2”及“了1+2”的使用上,皆多为冗余偏误。对于外国人学习教学应先由简到繁,介绍“了2”和相关句型,再介绍”了”和相关句型。
- 《Cross-Linguistic Error Types of Misused Chinese Based on Learners》基于东京大学语言学习者的语料库”Full Moon”,详细地研究了常见汉语学习者在书写时容易犯的错误,对错误类型进行了语言学角度的分类和定义。文章对日美两国学习者在学习时不同的量词使用错误进行了分析。
论文3:《Chinese Spelling Checker Based on Statistical Machine Translation》[8, Chiu, 2013]
文章综合使用了基于统计和基于规则的方法,规则召回的可能出错的位置通过统计翻译模型进行二次确认。作者将纠错视为一项翻译任务,即结合替换概率以及语言模型,将错误的句子翻译成正确的句子。
作者将纠错分三个阶段:
- 切词:降低候选的搜索空间
- 错误识别,找到可能错误的位置.(例如,两个以上的单字含更多错误。不过,这方法会受到切词粒度的影响,作者引入正确的web单字语言模型,甄别真实输入错误,即切词+使用词典+语料库语言模型方式进行错误判断。)
- 召回候选,错误纠正。召回候选使用引文[9, liu, 2011]的混淆集合(confusion set)。错误纠正套用SMT框架,定义翻译概率为: $$p(error|candi) = lo{g_{10}}\left( {{{freq\left( {error \to candi} \right)} \over {freq\left( {error \to candi} \right) - freq\left( {candi} \right)}}*\gamma } \right)$$ 公式按我的理解换了表述方式,其中${freq\left( {error \to candi} \right)}$表示替换为候选的次数,${freq\left( {candi} \right)}$表示为候选的次数。$\gamma $ 表示音频召回和字形召回的权重算子。解码的时候综合考虑翻译概率和语言模型,纠错比翻译任务少了排序一项。
文章未考虑删词和多词情况,作者建议的其他额外特征有:新词发现、POS、专名、ngram作为确认边界的词典。
论文4:《Chinese Word Spelling Correction Based on Rule Induction》[10, yeh, 2014]
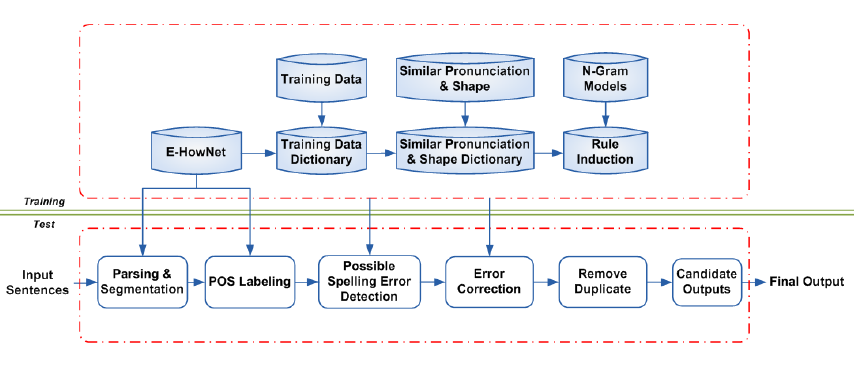
前置介绍E-Hownet为词库小组于2003年起开始建构繁体知识图谱。按下述系统流程图,分训练部分和测试部分。训练部分为了得到测试部分所需词典,加上同音词典和形近词典一共有三个词典。训练的流程分四个部分:
- 输入预处理,去除空格和圆括号等无关符号。
- 切词,标记POS。
- 规则衍生出候选词典,根据训练数据上下文及形似词典组合,在E-Hownet找到最佳词,形成候选词典。
测试阶段分为: - 输入预处理,去除空格和圆括号等无关符号。
- 切词,标记POS。
- 判断是否错误(若干规则)
a. 组合两个字以上的词(token),如果不在E-Hownet和训练集词典中(?)。
b. 四个字的词(token)过一次形近词典和音近词典、E-Hownet,如果没找到,则认为该位置的词不正确。
c. 通过pos规则找到“的、地、得”问题
d. 组合连续两个单字词(token),连接起来作为一个错词。
得到错误位置后,将其替换为音近或者形近字,保留存在于E-Hownet和训练集词典中的词。 - 多个候选以E-Hownet中下标小的为最佳。
论文5:《Understanding Error Correction and its Role as Part of the Communication Channel in Environments composed of Self-Integrating Systems》[12, lodwich, 2016]
这篇文章介绍了纠错在通讯系统里的重要性,篇幅较长60+。跟文本纠错有关的章节在2.4节”Error Correction in high-level languages”, 里面有句话颇有共鸣:“Error correction for high-level languages can demand a large amount of a priori knowledge which is usually too large to be provided as additional information by the sender and hence is provided directly to the receiver’s knowledge pool”。纠错是重资源依赖型,资源可以引申为与应用场景相关的先验信息。纠错如果需要继续深入,突破口应该在灵活多变的架构上,而不是万能纠错。
论文6:《Using Higher-level Linguistic Knowledge for Speech Recognition Error Correction in a Spoken Q/A Dialog》[13, jeong, 2004]
在对话系统中的中文纠错文章较少,这篇文章是韩国学者写的,对中文也有一定参考价值。耦合语音输入场景,作者在本文提出了基于音节的纠错模型。传统纠错常用的noisy channel模型,给定观测序列$O = {o_1},{o_2},...,{o_n}$,找到最佳的正确结果序列$W = {w_1},{w_2},...,{w_3}$。在语音识别纠错应用中,观测序列为语音识别模型输出的文本序列,我们需要找到用户在对应场景下想表达的正确结果。根据贝叶斯公式推导得:
$$\hat W = \arg \mathop {\max }\limits_W P\left( {W|O} \right) = \arg \mathop {\max }\limits_W P\left( W \right)P\left( {O|W} \right)$$
其中两项分别为语言模型$P\left( W \right)$和channel model$P\left( {O|W} \right)$。语言模型的一阶马尔可夫模型可以表达成:
$$P\left( W \right) = \mathop \prod \limits_i P\left( {{w_i}|{w_{1,i - 1}}} \right)$$
如果简单假设给定,结果序列的channel model的条件概率可以表达成:
$$P\left( {O|W} \right) = \prod\limits_i {P\left( {{o_i}|{w_i}} \right)} $$
这个假设太强,以至于无法处理如下”1对多”和”多对1”的两种情形。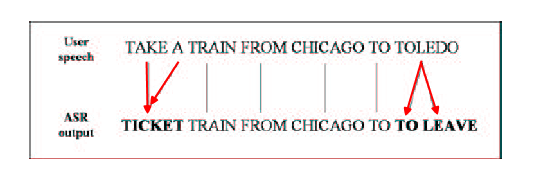 。
。
作者通过简化统计翻译模型IBM-Model-4利用了前一个位置的观察${{o_{i-1}}}$和输出结果${{w_{i-1}}}$,这部分最初工作来自(15, Brown, 1990)。
前面介绍了基于字的noisy channel model,韩语是表音文字,每个字可以根据其构成拼读出来,不需要另外单独的拼音系统,如果将字级别粒度进一步细化成音节级别,可以降低数据稀疏的问题。语音识别的输出序列由$W = {w_1},{w_2},...,{w_3}$替换为$S = {s_1},{s_2},...,{s_n}$,公式改造如下:
$$\hat W = \arg \mathop {\max }\limits_W P\left( {W|S} \right)$$
类似地,应用贝叶斯法则,在条件概率公式中引入音节的中间变量,进一步分解:
$$P\left( {w|s} \right) = {{P\left( {s|w} \right)P\left( w \right)} \over {P\left( s \right)}} \propto {P\left( {s|w} \right)P\left( w \right)} = \left( {\sum\limits_x {P\left( {s|x} \right)P\left( {x|w} \right)} } \right)P\left( w \right)$$
公式和原文略有不同原文公式最后为约等号$\approx P\left( {s|x} \right)P\left( {x|w} \right)P\left( w \right)$,感觉有点问题。最终公式形态为:
$$\hat W = \arg \mathop {\max }\limits_W P\left( W \right)P\left( {X|W} \right)P\left( {S|X} \right)$$
这个式子类似于语音识别里的隐马尔可夫模型。$P\left( {S|X} \right)$为声学模型,而$P\left( {X|W} \right)$为发音词典。在实验中作者用了2个字节的二阶马尔科夫模型。
简介文章中整体纠错流程:
- 语义级别纠错:使用Lexico-Semantic Pattern(LSP)[16, Jung, 2003] (LSP将query抽象为词法模板,类似POSTAG工作,举例 “Recretion coach”->”%hobby @position”)。通过预先收集的(话术)模板数据库进行语义级别纠错,在相同的LSP标签下找到数据库里面编辑距离最相似的候选,将语义级别LSP标签错误进行替换。
- 词汇级别纠错:对于LSP标签错误和词汇错误情况,通过前文介绍的基于音节的noisy channel model进行召回,并以动态规划方法进行动态求解。
论文7 《A hybrid approach to automatic Chinese text checking and error correction》[19, Ren, 2001]
作者在这篇论文里面提出使用规则+统计进行错误识别
- 规则,例如:中文语法中“数词+量词+名词”。通过语法规则进行错误识别。
- 统计
a. 词频
b. 相邻词之间的共现矩阵,例如“百度搜索”, “百度”和“搜索”共现
c. 相邻字之间的共现矩阵,例如“网盘”, “网”和“盘”共现
d. 相邻词内部的相邻字,例如“百度搜索”, “度”和“搜”
e. 字词位置关系。例如字位于词的第N个位置,也能提供很强的统计信息,约有1200个汉字只出现在词第一位,3008个汉字只会出现在第二个。
论文8 《Neural Language Correction with Character-Based Attention》[20, zhang, 2016]
这篇文章介绍NN在英文纠错里面的应用,简介如下:
- 作者使用了金字塔结构的GRU-RNN训练了一个纠错场景下的encoder decoder网络,解码过程使用了attention机制。
- 接着采用beam search算法,结合传统Ngram语言模型模型,进行最佳结果序列选择。
- 得到结果序列以后,再采用一个多层感知机分类器对纠错位置进行是否为正确纠错的判断。多层感知机使用编辑距离相关特征和词向量特征,其中词向量特征为GloVe训练出的100维向量。
[1] Yu J, Li Z. Chinese Spelling Error Detection and Correction Based on Language Model, Pronunciation, and Shape[C]// Cips-Sighan Joint Conference on Chinese Language Processing. 2014:220-223. (注:资源:形近词典,音近词典来自Yeh et al. 2013)
[2] Lee L H, Yu L C, Chang L P. Guest Editorial: Special Issue on Chinese as a Foreign Language[J]. 中文計算語言學期刊, 2015, 20:i-vi.
[3] Zhang S, Xiong J, Hou J, et al. HANSpeller++: A Unified Framework for Chinese Spelling Correction[C]// Eighth Sighan Workshop on Chinese Language Processing. 2015.
[4] Chuan-Jie Lin and Wei-Cheng Chu (2015). “A Study on Chinese Spelling Check Using Confusion Sets and N-gram Statistics,” International Journal of Computational Linguistics and Chinese Language Processing, to be appeared.
[5] Chang T H, Sung Y T, Hong J F. Automatically Detecting Syntactic Errors in Sentences Written by Learners of Chinese as a Foreign Language[J]. 中文計算語言學期刊, 2015, 20.
[6] Yeh J F, Yeh C K. Automatic Classification of the “De” Word Usage for Chinese as a Foreign Language[J]. 中文計算語言學期刊, 2015, 20.
[7] Mochizuki K, Sano H, Shen Y M, et al. Cross-Linguistic Error Types of Misused Chinese Based on Learners[J]. 中文計算語言學期刊, 2015, 20.
[8] Hsun-wen Chiu, Jian-cheng Wu, Jason S. Chang, Chinese Spelling Checker Based on Statistical Machine Translation, colling 2013, 2013
[9] Chao-Lin Liu, Min-Hua Lai, Kan-Wen Tien, Yi-Hsuan Chuang, Shih-Hung Wu, & Chia-Ying Lee (2011). Visually and phonologically similar characters in incorrect Chinese words: Analyses, identification, and applications. ACM Trans. Asian Lang, Inform. Process. 10, 2, Article 10, pages 39, June 2011.
[10] Yeh J F, Lu Y Y, Lee C H, et al. Chinese Word Spelling Correction Based on Rule Induction[C] // Cips-Sighan Joint Conference on Chinese Language Processing. 2014:139-145.
[11] JF Yeh,SF Li,MR Wu,WY Chen,MC Su Chinese Word Spelling Correction Based on N-gram Ranked Inverted Index List, In Six International Joint Conference on Natural Language Processing, 2013
[12] Lodwich A. Understanding Error Correction and its Role as Part of the Communication Channel in Environments composed of Self-Integrating Systems[J]. 2016.
[13] Jeong M, Kim B, Lee G G. Using higher-level linguistic knowledge for speech recognition error correction in a spoken Q/A dialog[C]// Hlt-Naacl Special Workshop on Higher-Level Linguistic Information for Speech Processing. 2004:48–55.
[14] Wang X, Li L. An N-gram based Chinese syllable evaluation approach for speech recognition error detection[C]// International Conference on Natural Language Processing and Knowledge Engineering, 2009. Nlp-Ke. IEEE, 2009:1-6.
[15] Voll K, Atkins S, Forster B. Improving the utility of speech recognition through error detection.[J]. Journal of Digital Imaging, 2008, 21(4):371.
[16] P. F. Brown, J. Cocke, S. A. Della Pietra, V. J. Della Pietra, F. Jelinek, J. D. Lafferty, R. L. Mercer, and P. S. Roossin. 1990. A Statistical Approach to Machine Translation. Computational Linguistics, 16(2):79-85
[17] Hanmin Jung, Gary Geunbae Lee, Wonseug Choi, KyungKoo Min, and Jungyun Seo. 2003. Multilingual question answering with high portability on relational databases. IEICE transactions on information and systems, E-86D(2):306-315.
[18] Lin C J, Chen S H. NTOU Chinese Grammar Checker for CGED Shared Task[C]// The Workshop on Natural Language Processing Techniques for Educational Applications. 2015:15-19. 作者根据语言模型定义了错误识别函数,使用svm判断出错位置。
[19] Ren F, Shi H, Zhou Q. A hybrid approach to automatic Chinese text checking and error correction[C]// IEEE International Conference on Systems, Man, and Cybernetics. IEEE, 2001:1693-1698 vol.3.
[20] Xie Z, Avati A, Arivazhagan N, et al. Neural Language Correction with Character-Based Attention[J]. 2016.
论文TODO List:
Correcting Chinese Spelling Errors with Word Lattice Decoding
Spelling checking using conditional random fields with feature induction for secondary language learners
Improving the Utility of Speech Recognition Through Error Detection
A METHODOLOGY OF ERROR DETECTION: IMPROVING SPEECH RECOGNITION IN RADIOLOGY
DIRECTED AUTOMATIC SPEECH TRANSCRIPTION ERROR CORRECTION USING BIDIRECTIONAL LSTM
A rule based Chinese spelling and grammar detection system utility. 2012.
(注://历年举办纠错大会SIGHAN workshop自IJCNLP 2013年开始。)
后续会整理出一些ctr和online learning 相关的笔记