浅谈Batch Normalization及其Caffe实现
摘要:2015年2月份,Google和MSRA的paper相继在arxiv.org上横空出世,宣布在ImagenNet图像数据集上取得了比人类更高的识别能力. 此突破意义重大,文章发布后引起一片热潮,在图像领域具有普适的应用.
本文中笔者仅就Google的Batch Normalization谈谈粗浅的理解.
Motivation
1.1 internal convariate shit
传统的浅层学习模型,如单层的logistic regression, SVMs以及2层结构的FMs等模型,每次更新参数均从稳定的训练数据上拟合. 深度学习因其多层结构,浅层输出作为下一层输入.除了梯度消失问题外,在学习过程中,每层网络的参数不断更新,导致下一层输入的分布不断变化. 因而无法跟浅层模型一样,每次都在稳定的数据上学习参数. 除了降低学习率外,还要初始化一组良好的参数,调得一手好参.
1.2 为什么要初始化一组良好的参数
学习过UFLDL或者做过图像实验的同学会发现对数据进行预处理,例如PCA Whitening或者简单的z-score都是可以加速收敛的.
首先图像数据是局部高度相关的,并且个维度上的数据取值在[0,255]之间. 简化到2维,图像数据仅会落到第一象限,如下图: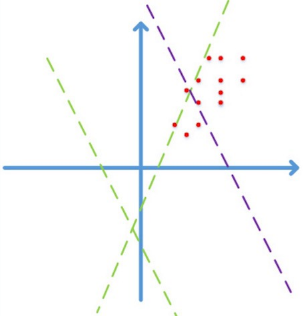
图片来自happynear的博客2
假设激活函数为ReLu$f(x) = \text{max}(Wx + b)$, 如果不通过精心设计或者fine-tune,而随机初始化$W$, 学习的前期阶段很可能是图中的绿色虚线,需要经过长时间的迭代才能收敛到紫色虚线,得到一个好的拟合结果。
如果对数据做预处理,例如z-score/PCA whitening等线性变化,映射到0均值单位方差的平移后空间里,那么收敛效果会有显著提升。因为减去均值后,数据能分散到各个象限;更进一步的,对数据做去相关操作,提高收敛效率.
1.3 为什么做的是线性变换而不能做非线性变换呢?
Batch Normalization是数据层面的改进,要保留数据的原貌,即保留特征的非线性关系.
Normalization via Mini-Batch Statistics

前向反馈时,在每个Batch中,从特征维度上计算出mini-batch和mini-batch variance之后完成normalization.
理想情况下,均值和方差应该是在整个数据集上计算的,然而不能穿越得到unseen data,因此,退而求其次,用Batch中统计的均值和方差作为整个数据集的估计.
完成normalization之后算法似乎该结束了,但是如果把特征都normalize到$\cal{N}(0,1)$,那么因为特征只在激活函数上线性区域上激活,会降低特征的表达能力. 如下图虚线和Sigmoid曲线的重叠的部分.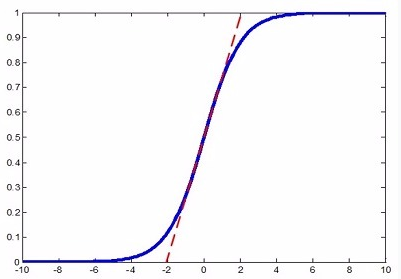
容易混淆的是,Hinton老爷子曾在公开课Neural Networks for Machine Learning3里提到神经网络的weight应该初始化在$\cal{N}(0,1)$附近,防止梯度消失.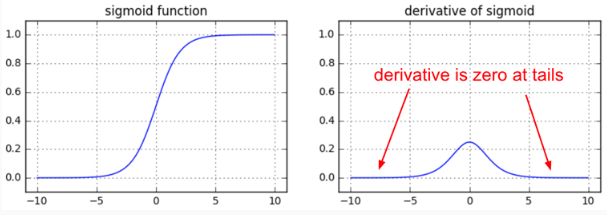
但是,如果使用PReLU或者ELU等激活函数,是不会有这个问题的!
针对上述问题,在算法结束之前,作者对normalization之后的数据$\hat{x_i}$设置了两个参数$\gamma$和$\beta$. 很显然如果$\gamma=\sqrt{\sigma^2_{\beta}}$,$\beta=\mu_{\beta}$,那么对$x_i$ scale
and shift之后的$y_i$就还原成$x_i$了. 至于是否需要对$y_i$进行还原,由构建好的模型自动从训练数据中学习决定, learning from data.
反向传播时,SGD也在Batch中计算,梯度公式很简单,请大家停下10分钟,在白纸上推导一遍,保证清楚理解链式法则计算梯度的思路. 这很重要,因为目前所有的学习算法都是基于链式法则的反向传播.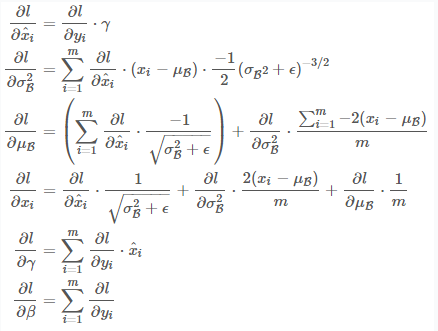
Implementation in Caffe
笔者接下来介绍Batch Normalization在Caffe中的实现.
实际应用中,$\mu_{\beta}$和$\sigma^2_{\beta}$通常是在训练集上计算,测试的时候直接使用训练时计算得到的值. 此外,Batch Normalization Layer的backward pass实际并没有被调用,因此笔者仅分析forward pass部分的代码.
首先Batch Normalization在proto中默认参数配置如下:
因为一些历史原因(可能是scale and shift只对使用sigmoid作为激活函数有效), Caffe的normalize step 和scale and shift step至今不在同一个layer中实现, 导致很多人在使用的时候经常出现不知道该怎么用或者这么用对不对的问题. 笔者建议参考ResNet4,并建议在BatchNorm中不显示配置batch_norm_param,而是有代码运行时自动判断是否use_global_stats,此外不建议做scale and shift step,因为sigmoid function效果通常是很差的,导致更多的是一开始就选择PReLu等激活函数:
详细代码走读参见笔者的github.
总结
本文首先解释了Batch Normalization的motivation以及该方法为什么work. 接着对算法内容进行详解,给出并建议读者朋友们动手在白纸上推导反向传播计算$\mu_{\beta}$和$\sigma^2_{\beta}$的梯度公式. 最后在github上提供了一份Caffe的bn代码走读.
欢迎并鼓励对本文和github上代码走读有不同见解的朋友们留言或者联系本站站长!
参考文献
- Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
- 《Batch Normalization Accelerating Deep Network Training by Reducing Internal Covariate Shift》阅读笔记与实现
- Neural Networks for Machine Learning
- ResNet-152-deploy
作者微博:@ryyen