简述FastDBT和LightGBM中GBDT的实现
FastDBT和LightGBM在XGBoost之后提出,FastBDT针对多类别问题进行了优化,从实现层面获得了更快的训练速度,LightGBM则在树的生成进行了改进,文章按以下思路介绍
- FastDBT简介及代码走读,LightGBM简介
- 从算法层面讨论下三者的异同点
FastDBT篇
树模型从模型层面和实现层面两种可行的改进方式:1.模型层面的改进:如SGBDT采用的样本采样方式[1],或者对弱作用特征的剪枝[2]。2.实现层面的改进,见引文[3].FastDBT延续自SGBDT,SGBDT在每层树的构建中并非所有样本都使用到,按参数$\alpha$对数据进行随机采样。
FastDBT有如下三个实现层面上的加速:
- 数据在内存的存储方式,分为两种a.结构体数据,b.数组结构体,如下图1。区别在于当对其中一维特征进行遍历的时候,按数组结构体的方式存储使得内存连续,提升内存访问速度。
- 将正例负例进行区分存储,减少一半左右的计算累计直方图(calculation of the cumulative probability histograms, CPH)缓存占用,同时节约了if判断条件跳转的浪费。
- 同层节点并行计算。由于每层的节点的数据来自于被父节点分割的子集,FastBDT在对不同的节点同时计算CPH(临时存储多个节点点的CPH),可以连续进行内存访问避免跳跃。

下面进行FastDBT建树部分代码走读:
有几个实现细节比较trick需要提一下
FeatureBinning的内部实现采用了二分查找树(调了几个小时代码没弄明白,幸亏Thomas解答并帮忙增加了注释)
特征值分桶核心代码:12345678910//枚举每一层树for(uint64_t iLevel = 0; iLevel < nLevels; ++iLevel)://桶的数目doubleconst uint64_t nBins = (1 << iLevel)//枚举每个桶for(uint64_t iBin = 0; iBin < nBins; ++iBin) {//记特征值下标为 size/2^(iLevel+1)+iBin*size/2^iLevel//第bin_index指向的有序特征的对应二分查找位置binning[++bin_index] = \first[(size >> (iLevel+1)) + ((iBin*size) >> iLevel)]ForestBuilder类的初始化时完成SGBDT每一棵树的级联
boosting过程的核心代码:1234567891011121314//生成nTrees棵树for(unsigned int iTree = 0; iTree < nTrees; ++iTree):// Update the event weights according to their F value// 使用对应的F值进行更新每个样本的权重,F值为pseudo_responseupdateEventWeights(sample)// Prepare the flags of the events// 根据randRatio进行采样,eventsamples内有flag可以标记样本是否可用prepareEventSample(sample, randRatio, sPlot )// TreeBuilder类进行单棵树的生成, nLayersPerTree为树的层TreeBuilder builder(nLayersPerTree, sample)//将生成的树加入到森林中forest.push_back( Tree<unsigned int>( builder.GetCuts(), \builder.GetNEntries(), builder.GetPurities(), \builder.GetBoostWeights() ) )TreeBuilder类完成单棵树的生成
TreeBuilder核心代码走读:1234567891011121314151617//生成每一棵树需要探索的节点,存在nodes列表for(unsigned int iLayer = 0; iLayer <= nLayers; ++iLayer)for(unsigned int iNode = 0; iNode < (1<<iLayer); ++iNode)nodes.push_back( Node(iLayer, iNode) );// 每棵树的节点是从顶向下,从左到右生成,// 树是贪心法生成,我们迭代计算每一层的节点// 对于不同的分裂节点和特征,生成正负例的累计直方图for(unsigned int iLayer = 0; iLayer < nLayers; ++iLayer)//计算累计直方图,signal,background分别计算//由于signal,background在存储上物理分离,可以进行连续访问CumulativeDistributions CDFs(iLayer, sample)//选择合适的特征和值,更新到当前节点UpdateCuts(CDFs, iLayer)//采样数据,SGBDT特有操作UpdateFlags(sample)//根据分裂节点划分样本UpdateEvents(sample, iLayer)计算累计直方图,得到正例和负例的累计直方图
1234567891011121314//对于所有在这一层的节点,每一个特征,填充累计直方图bins//将每个特征的bins进行填充for(int iEvent = firstEvent; iEvent < lastEvent; ++iEvent)for(int iFeature = 0; iFeature < nFeatures; ++iFeature )int subindex = nBinSums[iFeature] + values.Get(iEvent,iFeature);bins[index+subindex] += weights.Get(iEvent);//在前一步得到的bins中,顺序累计所有的桶内的值,得到累计直方图for(int iNode = 0; iNode < nNodes; ++iNode) {for(int iFeature = 0; iFeature < nFeatures; ++iFeature)// 从位置2起始是因为0位置放置非自然数for(int iBin = 2; iBin < nBins[iFeature]; ++iBin)unsigned int index = iNode*nBinSums.back() \+ nBinSums[iFeature] + iBin;bins[index] += bins[index-1];根据正负例的累计直方图,查找最优分裂点
123456789101112131415Weight currentLoss = LossFunction(signal, bckgrd);//遍历每一个特征的每一个桶for(int iFeature = 0; iFeature < nFeatures; ++iFeature)// 从位置2起始是因为0位置放置非自然数for(unsigned int iCut = 2; iCut < nBins[iFeature]; ++iCut) {Weight s = CDFs.GetSignal(iNode, iFeature, iCut-1);Weight b = CDFs.GetBckgrd(iNode, iFeature, iCut-1);//计算基尼系数,从函数看这里应该是简化的基尼系数Weight currentGain = currentLoss - \LossFunction( signal-s, bckgrd-b ) - LossFunction( s, b );if( cut.gain <= currentGain )cut.gain = currentGain;cut.feature = iFeature;cut.index = iCut;cut.valid = true;
到这里为止,我们已经看完几个重要的模块,关于FastBDT的介绍告一段落,有需要的同学可以继续在github上阅读更详细的代码,附上代码仓库地址。
LightGBM篇
LightGBM主要思路还在GBDT框架内,重复部分不再赘述,这篇我打算偷个懒,把LightGBM的新特性细数一遍,当然附上详细的算法文档,里面介绍很到位:《LightGBM中的GBDT实现》@chenghuige 网盘地址,代码仓库地址。
- 单机采用Histogram算法,这点同FastBDT一样,而XGboost单机是Greedy进行的。
- 大多数GBDT工具(FastDBT/XGboost)按逐层(level wise)的方式进行生长,而LightGBM从当前节点出发找到一个分类增益最大的叶子,然后继续分裂(leaf wise),如此循环。优点是在分类次数相同的前提下,可以得到更好的精度。缺点可能会导致树的深度过大,解决方式是增加最大深度限制。
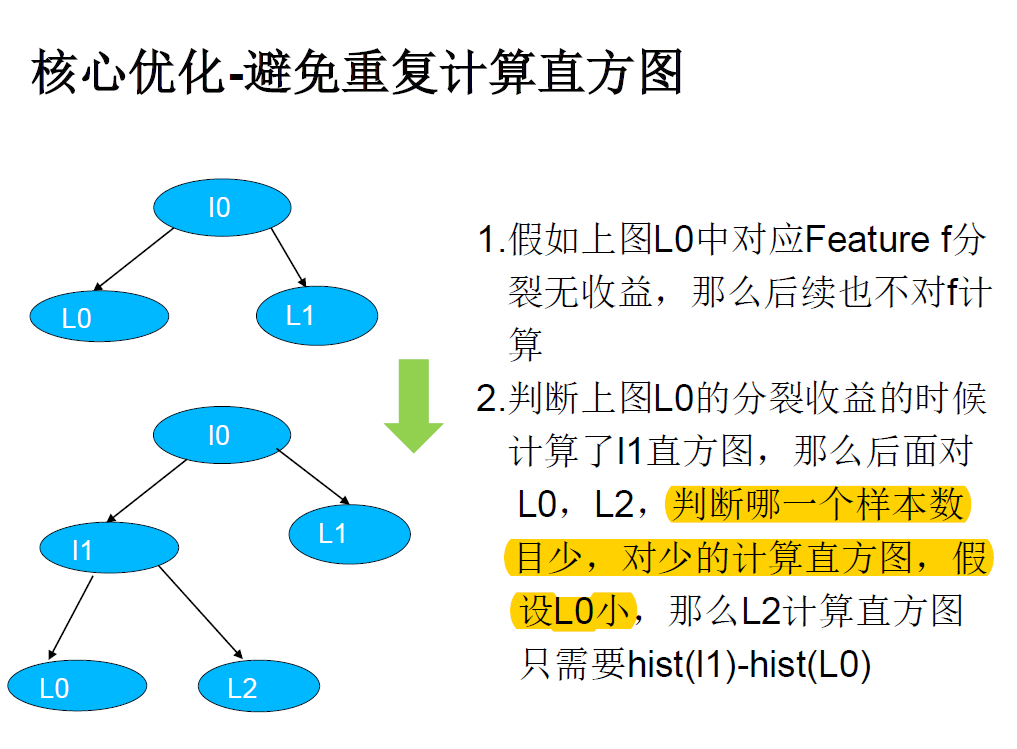
- 计算直方图时的优化:避免重复计算直方图,构造一个叶子的直方图后,可以用求差的方式得到它兄弟叶子的直方图。
XGboost/FastGBM/LightGBM,三者的异同点
三者都是GBDT很好的实现,枚举几点异同:
- FastBDT在单机分类问题进行了极致的优化和探索,当然也限制了其在回归问题的应用。而XGboost和LightGBM可以用于分类和回归,并很好支持了并行化。
- XGboost单机版本Greedy进行,并对每个特征有进行pre-sort操作,带了额外的开销。这点在FastBDT和LightGBM中进行了规避。
- FastBDT中可以看到受SGBDT影响较大,XGboost也支持对样本的采样,LightGBM未做考核,暂无结论。
- LightGBM选择生长树的方式选择分类增益最大叶子进行生长,而XGboost和FastBDT是逐层进行。
此外,XGboost在业界运用较多,对各大平台很友好,目前仍有活跃着很多贡献者,最新进展为《Support Dropout on XGBoost》
引文:
[0]Keck T. FastBDT: A speed-optimized and cache-friendly implementation of stochastic gradient-boosted decision trees for multivariate classification[J]. 2016.
[1]Tong Zhang Rie Johnson. Learning nonlinear functions using regularized greedy forest.IEEE Transactions on Pattern Analysis and Machine Intelligence, 36(5):942–954, May 2014. doi: 10.1109/TPAMI.2013.159. PDF
[2]Ron Appel, Thomas Fuchs, Piotr Dollar, and Pietro Perona. Quickly boosting decision trees – pruning underachieving features early. In Sanjoy Dasgupta and David Mcallester, editors, Proceedings of the 30th International Conference on Machine Learning (ICML-13), volume 28, pages 594–602. JMLR Workshop and Conference Proceedings, May 2013. PDF .
Tong Zhang Rie Johnson. Learning nonlinear functions using regularized greedy forest. IEEE Transactions on Pattern Analysis and Machine Intelligence, 36(5):942–954, May 2014. doi: 10.1109/TPAMI.2013.159. PDF.
[4]如何看待微软新开源的LightGBM?, lightGBM作者@guolinke
PS. 家里有事,穿插了一次部门bui,没时间码字,sorry,接下来探索一下embeding方面的文章。
ShawnXiao@baidu